Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
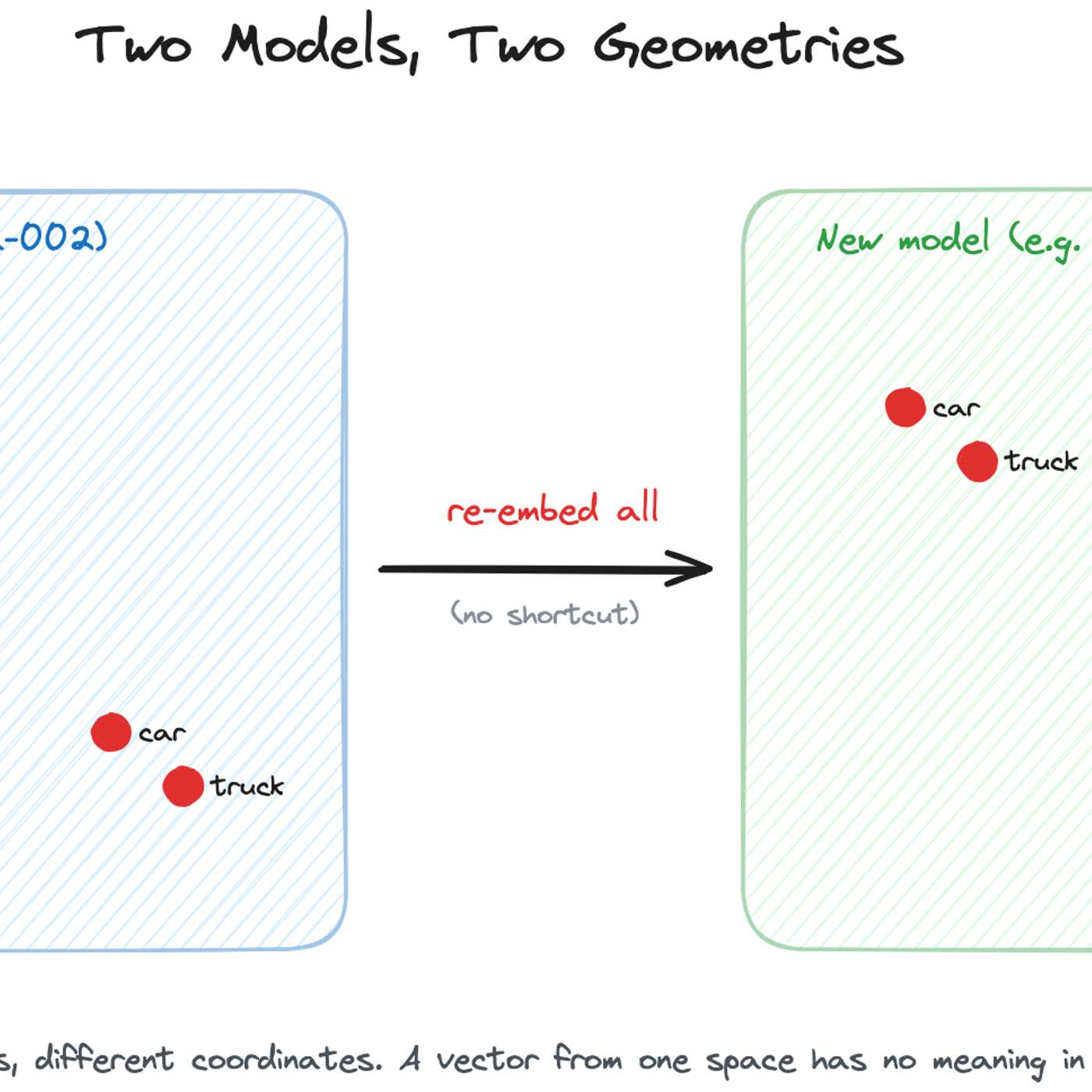
The most common and robust method for migrating embedding models is to build a completely new vector index in parallel using the new model. While the old index serves live traffic, the new one is built, validated via shadow scoring, and then traffic is cut over with an alias swap, ensuring zero downtime.
Related Insights
For systems where a full parallel index is too expensive, a gradual migration is possible. By using two vector fields in each document (one for the old model, one for the new), queries can be run against both fields simultaneously. Results are then merged using Reciprocal Rank Fusion (RRF), which works even though the models' similarity scores are incomparable.
Managed vector databases are convenient, but building a search engine from scratch using a library like FAISS provides a deeper understanding of index types, latency tuning, and memory trade-offs, which is crucial for optimizing AI systems.

While academic research explores techniques like 'embedding space alignment' to avoid costly re-embeddings, no major company has publicly confirmed using them in production. Industry accounts from Uber, Pinterest, and Google all describe full, parallel re-embedding as the current, practical standard, highlighting a significant gap between research and real-world adoption.
To avoid frantic, high-pressure migrations when an embedding model is deprecated, teams should treat model selection as a dependency that requires planned updates, like any other software library. This mindset shifts the process from an emergency scramble to routine, planned maintenance, making upgrades predictable and manageable.
Simply "scaling up" (adding more GPUs to one model instance) hits a performance ceiling due to hardware and algorithmic limits. True large-scale inference requires "scaling out" (duplicating instances), creating a new systems problem of managing and optimizing across a distributed fleet.

A typical A/B test re-ranks the same set of results. However, changing the embedding model alters the fundamental retrieval step, meaning the two versions return entirely different sets of documents for the same query. This complicates analysis, as performance differences reflect both model quality and the content of the newly retrieved documents.
Google's new state-of-the-art Deep Research agents are still powered by the older Gemini 3.1 Pro model. Their significant performance improvements come entirely from 'harness upgrades' and additional inference techniques. This demonstrates that the systems, tools, and processes surrounding a model are now a primary driver of capability, not just the raw power of the base model itself.

To fully leverage rapidly improving AI models, companies cannot just plug in new APIs. Notion's co-founder reveals they completely rebuild their AI system architecture every six months, designing it around the specific capabilities of the latest models to avoid being stuck with suboptimal implementations.

When considering a significant business change, like migrating to a new platform, avoid disrupting your primary revenue source. MarketBeat's founder advises creating a new, separate project to test the change, protecting the "goose that's laying golden eggs."

Since true AI explainability is still elusive, a practical strategy for managing risk is benchmarking. By running a new AI model alongside the current one and comparing their outputs on a defined set of tests, companies can identify and address issues like bias or unexpected behavior before a full rollout.
