Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
For systems where a full parallel index is too expensive, a gradual migration is possible. By using two vector fields in each document (one for the old model, one for the new), queries can be run against both fields simultaneously. Results are then merged using Reciprocal Rank Fusion (RRF), which works even though the models' similarity scores are incomparable.
Related Insights
Systems like FAISS are optimized for vector similarity search and do not store the original data. Engineers must build and maintain a separate system to map the returned vector IDs back to the actual documents or metadata, a crucial step for production applications.

For millions of vectors, exact search (like a FAISS flat index) is too slow. Production systems use Approximate Nearest Neighbor (ANN) algorithms which trade a small amount of accuracy for orders-of-magnitude faster search performance, making large-scale applications feasible.
To move beyond keyword search in their media archive, Tim McLear's system generates two vector embeddings for each asset: one from the image thumbnail and another from its AI-generated text description. Fusing these enables a powerful semantic search that understands visual similarity and conceptual relationships, not just exact text matches.

Managed vector databases are convenient, but building a search engine from scratch using a library like FAISS provides a deeper understanding of index types, latency tuning, and memory trade-offs, which is crucial for optimizing AI systems.
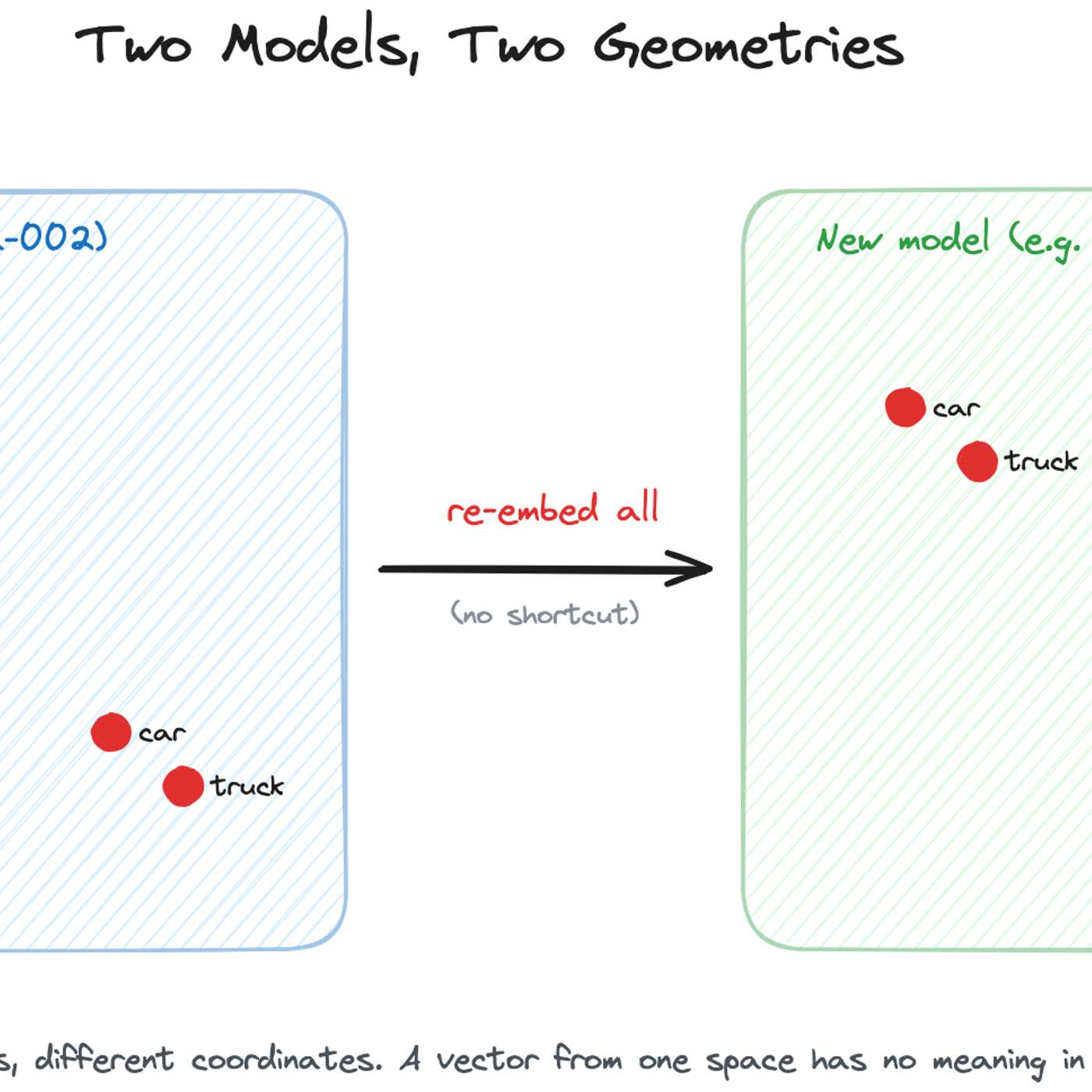
While academic research explores techniques like 'embedding space alignment' to avoid costly re-embeddings, no major company has publicly confirmed using them in production. Industry accounts from Uber, Pinterest, and Google all describe full, parallel re-embedding as the current, practical standard, highlighting a significant gap between research and real-world adoption.
To avoid frantic, high-pressure migrations when an embedding model is deprecated, teams should treat model selection as a dependency that requires planned updates, like any other software library. This mindset shifts the process from an emergency scramble to routine, planned maintenance, making upgrades predictable and manageable.
A typical A/B test re-ranks the same set of results. However, changing the embedding model alters the fundamental retrieval step, meaning the two versions return entirely different sets of documents for the same query. This complicates analysis, as performance differences reflect both model quality and the content of the newly retrieved documents.
Vector search excels at semantic meaning but fails on precise keywords like product SKUs. Effective enterprise search requires a hybrid system combining the strengths of lexical search (e.g., BM25) for keywords and vector search for concepts to serve all user needs accurately.

The nature of Retrieval-Augmented Generation (RAG) is evolving. Instead of a single search to populate an initial context window, AI agents are now performing numerous concurrent queries in a single turn. This allows them to explore diverse information paths simultaneously, driving new database requirements.
The most common and robust method for migrating embedding models is to build a completely new vector index in parallel using the new model. While the old index serves live traffic, the new one is built, validated via shadow scoring, and then traffic is cut over with an alias swap, ensuring zero downtime.