Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Since true AI explainability is still elusive, a practical strategy for managing risk is benchmarking. By running a new AI model alongside the current one and comparing their outputs on a defined set of tests, companies can identify and address issues like bias or unexpected behavior before a full rollout.

Related Insights
Standardized benchmarks for AI models are largely irrelevant for business applications. Companies need to create their own evaluation systems tailored to their specific industry, workflows, and use cases to accurately assess which new model provides a tangible benefit and ROI.

After an initial analysis, use a "stress-testing" prompt that forces the LLM to verify its own findings, check for contradictions, and correct its mistakes. This verification step is crucial for building confidence in the AI's output and creating bulletproof insights.

Treating AI risk management as a final step before launch leads to failure and loss of customer trust. Instead, it must be an integrated, continuous process throughout the entire AI development pipeline, from conception to deployment and iteration, to be effective.

Instead of treating a complex AI system like an LLM as a single black box, build it in a componentized way by separating functions like retrieval, analysis, and output. This allows for isolated testing of each part, limiting the surface area for bias and simplifying debugging.

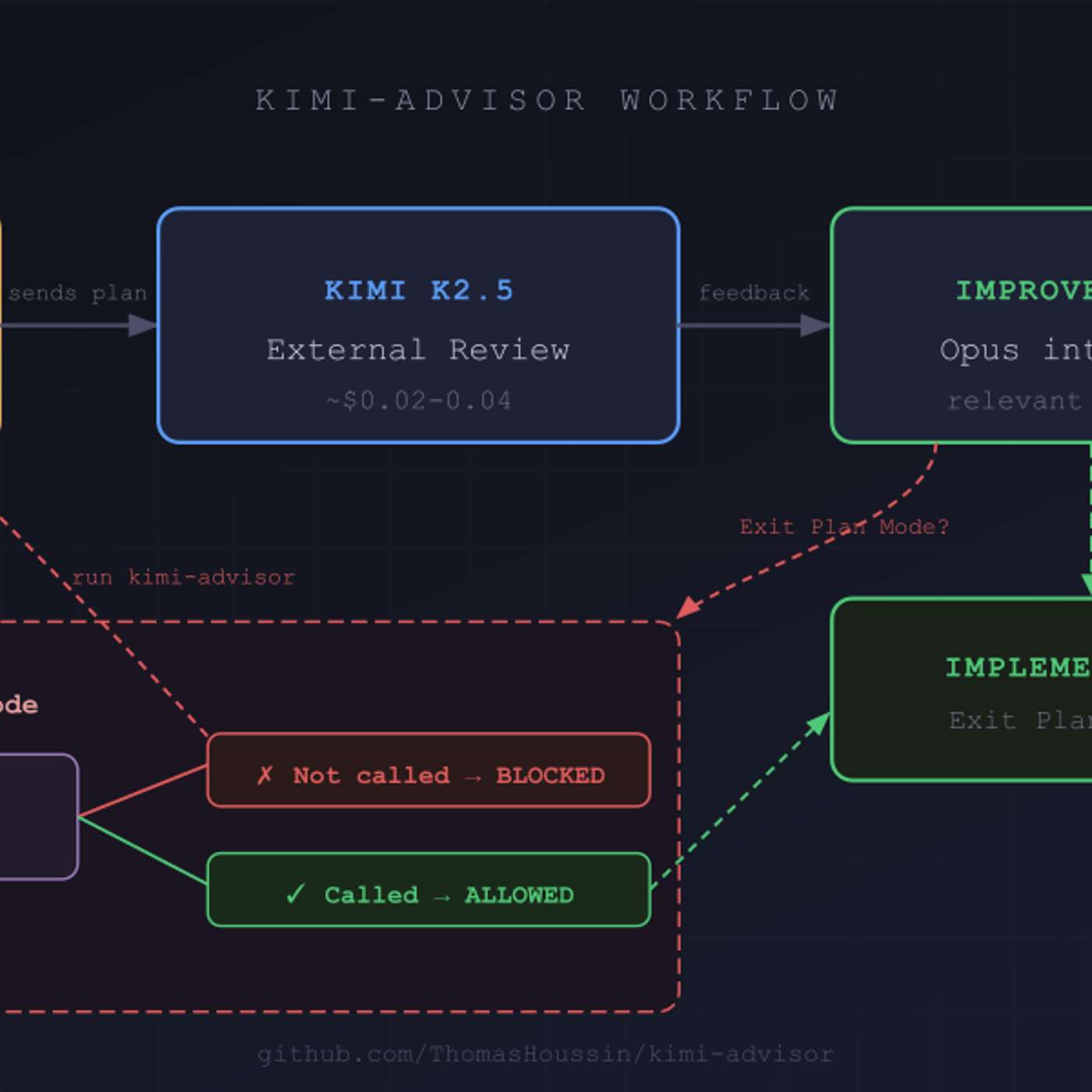
To improve code quality, use a secondary AI model from a different provider (e.g., Moonshot AI's Kimi) to review plans generated by a primary model (e.g., Anthropic's Claude). This introduces cognitive diversity and avoids the shared biases inherent in a single model family, leading to a more robust and enriching review process.
The rapid improvement of AI models is maxing out industry-standard benchmarks for tasks like software engineering. To truly understand AI's impact and capability, companies must develop their own evaluation systems tailored to their specific workflows, rather than waiting for external studies.

A comprehensive approach to mitigating AI bias requires addressing three separate components. First, de-bias the training data before it's ingested. Second, audit and correct biases inherent in pre-trained models. Third, implement human-centered feedback loops during deployment to allow the system to self-correct based on real-world usage and outcomes.
All data inputs for AI are inherently biased (e.g., bullish management, bearish former employees). The most effective approach is not to de-bias the inputs but to use AI to compare and contrast these biased perspectives to form an independent conclusion.

Instead of waiting for external reports, companies should develop their own AI model evaluations. By defining key tasks for specific roles and testing new models against them with standard prompts, businesses can create a relevant, internal benchmark.

To stay on the cutting edge, maintain a list of complex tasks that current AI models can't perform well. Whenever a new model is released, run it against this suite. This practice provides an intuitive feel for the model's leap in capability and helps you identify when a previously impossible workflow becomes feasible.
![How Investors are using AI - [Business Breakdowns, EP.240] thumbnail](https://megaphone.imgix.net/podcasts/f879fb14-024c-11f1-9c47-7bea8da34fd0/image/56ffcbcc6e03475c408ac0e35a01510d.jpg?ixlib=rails-4.3.1&max-w=3000&max-h=3000&fit=crop&auto=format,compress)