Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
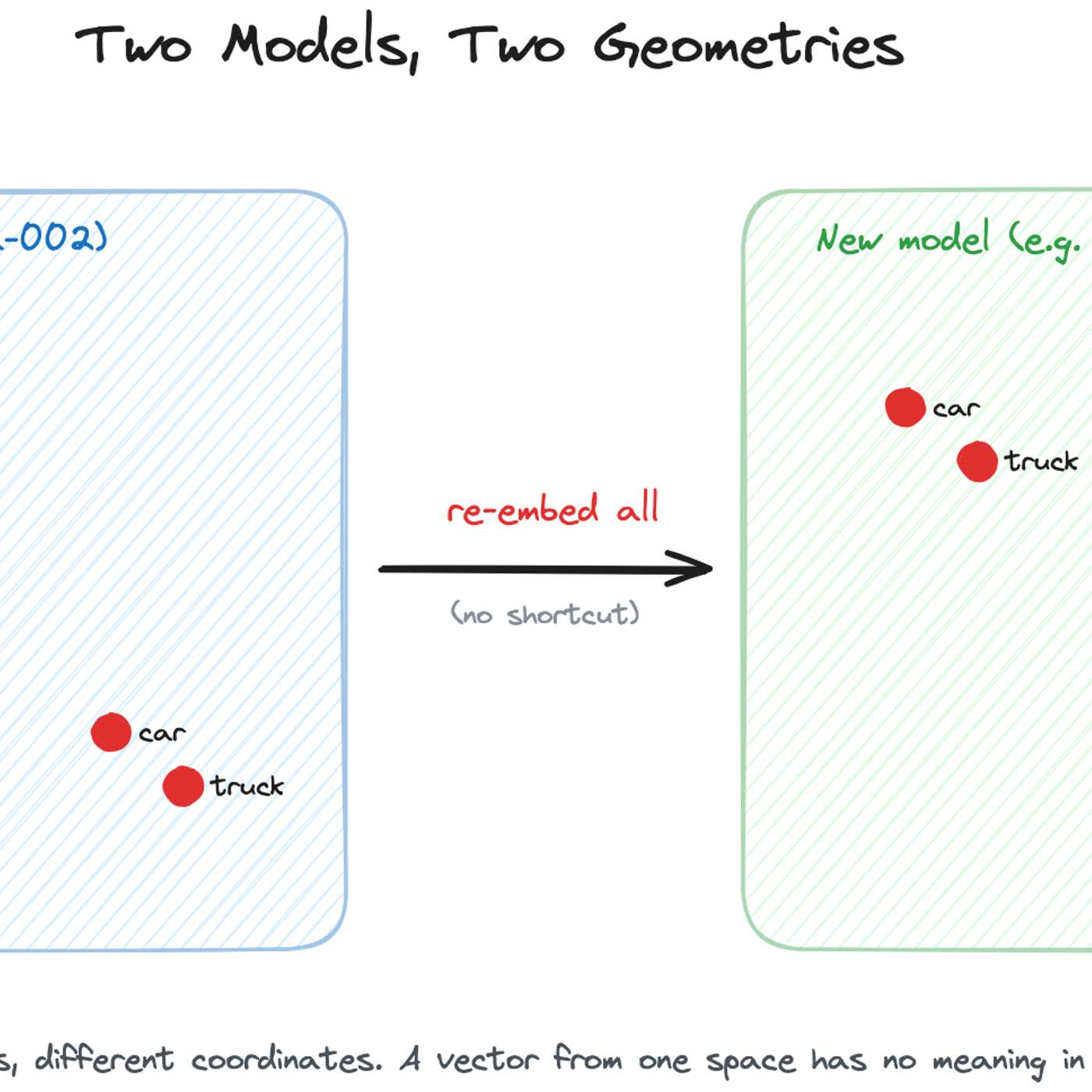
A typical A/B test re-ranks the same set of results. However, changing the embedding model alters the fundamental retrieval step, meaning the two versions return entirely different sets of documents for the same query. This complicates analysis, as performance differences reflect both model quality and the content of the newly retrieved documents.
Related Insights
While academic research explores techniques like 'embedding space alignment' to avoid costly re-embeddings, no major company has publicly confirmed using them in production. Industry accounts from Uber, Pinterest, and Google all describe full, parallel re-embedding as the current, practical standard, highlighting a significant gap between research and real-world adoption.
Public leaderboards like LM Arena are becoming unreliable proxies for model performance. Teams implicitly or explicitly "benchmark" by optimizing for specific test sets. The superior strategy is to focus on internal, proprietary evaluation metrics and use public benchmarks only as a final, confirmatory check, not as a primary development target.

As benchmarks become standard, AI labs optimize models to excel at them, leading to score inflation without necessarily improving generalized intelligence. The solution isn't a single perfect test, but continuously creating new evals that measure capabilities relevant to real-world user needs.

To avoid frantic, high-pressure migrations when an embedding model is deprecated, teams should treat model selection as a dependency that requires planned updates, like any other software library. This mindset shifts the process from an emergency scramble to routine, planned maintenance, making upgrades predictable and manageable.
The gap between benchmark scores and real-world performance suggests labs achieve high scores by distilling superior models or training for specific evals. This makes benchmarks a poor proxy for genuine capability, a skepticism that should be applied to all new model releases.

Seemingly simple benchmarks yield wildly different results if not run under identical conditions. Third-party evaluators must run tests themselves because labs often use optimized prompts to inflate scores. Even then, challenges like parsing inconsistent answer formats make truly fair comparison a significant technical hurdle.
Metrics like BLEU and ROUGE compare word overlap, not meaning. An LLM's output like "the cat is on the bed" could be semantically opposite to the ground truth "the cat is on the mat" but still score high. This highlights the need for more sophisticated, meaning-aware evaluations like LLM-as-a-judge.

Despite mature backtesting frameworks, Intercom repeatedly sees promising offline results fail in production. The "messiness of real human interaction" is unpredictable, making at-scale A/B tests essential for validating AI performance improvements, even for changes as small as a tenth of a percentage point.

Good Star Labs found GPT-5's performance in their Diplomacy game skyrocketed with optimized prompts, moving it from the bottom to the top. This shows a model's inherent capability can be masked or revealed by its prompt, making "best model" a context-dependent title rather than an absolute one.

Since true AI explainability is still elusive, a practical strategy for managing risk is benchmarking. By running a new AI model alongside the current one and comparing their outputs on a defined set of tests, companies can identify and address issues like bias or unexpected behavior before a full rollout.
