Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
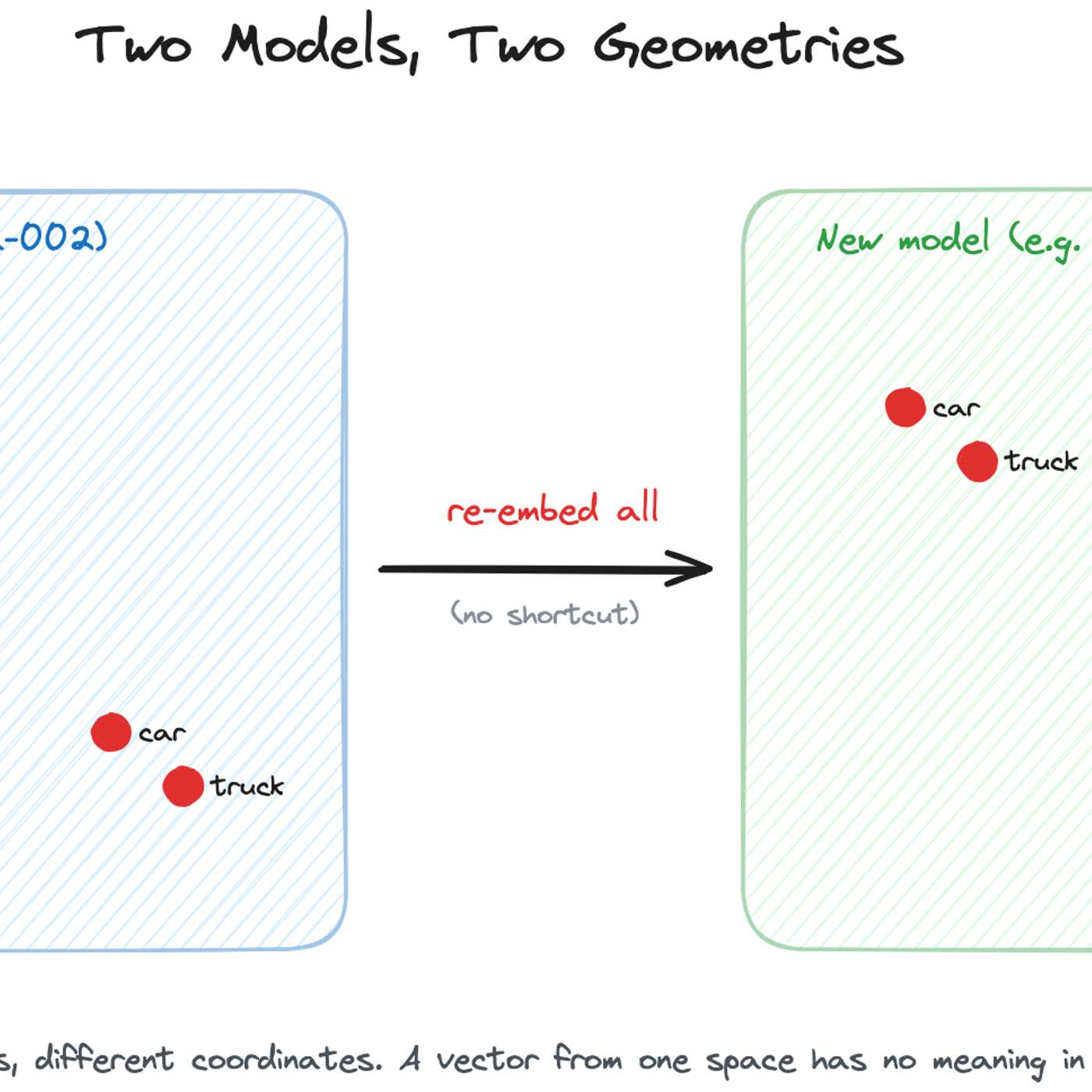
While academic research explores techniques like 'embedding space alignment' to avoid costly re-embeddings, no major company has publicly confirmed using them in production. Industry accounts from Uber, Pinterest, and Google all describe full, parallel re-embedding as the current, practical standard, highlighting a significant gap between research and real-world adoption.
Related Insights
Google's Embedding 2 model is a significant infrastructure upgrade because it is 'natively multimodal.' This allows AI to directly understand and retrieve images, diagrams, and text without first converting non-text data into lossy captions. This makes internal knowledge bases and co-pilots dramatically more effective and accurate for enterprises.

For systems where a full parallel index is too expensive, a gradual migration is possible. By using two vector fields in each document (one for the old model, one for the new), queries can be run against both fields simultaneously. Results are then merged using Reciprocal Rank Fusion (RRF), which works even though the models' similarity scores are incomparable.
Instead of expensive, static pre-training on proprietary data, enterprises prefer RAG. This approach is cheaper, allows for easy updates as data changes, and benefits from continuous improvements in foundation models, making it a more practical and dynamic solution.

To avoid frantic, high-pressure migrations when an embedding model is deprecated, teams should treat model selection as a dependency that requires planned updates, like any other software library. This mindset shifts the process from an emergency scramble to routine, planned maintenance, making upgrades predictable and manageable.
A typical A/B test re-ranks the same set of results. However, changing the embedding model alters the fundamental retrieval step, meaning the two versions return entirely different sets of documents for the same query. This complicates analysis, as performance differences reflect both model quality and the content of the newly retrieved documents.
The public-facing models from major labs are likely efficient Mixture-of-Experts (MOE) versions distilled from much larger, private, and computationally expensive dense models. This means the model users interact with is a smaller, optimized copy, not the original frontier model.
![[LIVE] Anthropic Distillation & How Models Cheat (SWE-Bench Dead) | Nathan Lambert & Sebastian Raschka thumbnail](https://substackcdn.com/feed/podcast/1084089/post/189277598/ca7468da5614a246d2906ee8926f6de7.jpg)
By training a smaller, specialized model where company data is in the weights, firms avoid the high token costs of repeatedly feeding context to large frontier models. This makes complex, data-intensive workflows significantly cheaper and faster.

As enterprises scale AI, the high inference costs of frontier models become prohibitive. The strategic trend is to use large models for novel tasks, then shift 90% of recurring, common workloads to specialized, cost-effective Small Language Models (SLMs). This architectural shift dramatically improves both speed and cost.

The most common and robust method for migrating embedding models is to build a completely new vector index in parallel using the new model. While the old index serves live traffic, the new one is built, validated via shadow scoring, and then traffic is cut over with an alias swap, ensuring zero downtime.
Despite constant new model releases, enterprises don't frequently switch LLMs. Prompts and workflows become highly optimized for a specific model's behavior, creating significant switching costs. Performance gains of a new model must be substantial to justify this re-engineering effort.