Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
The nature of Retrieval-Augmented Generation (RAG) is evolving. Instead of a single search to populate an initial context window, AI agents are now performing numerous concurrent queries in a single turn. This allows them to explore diverse information paths simultaneously, driving new database requirements.
Related Insights
The significance of a massive context window isn't just about processing more data. It enables AI to identify and synthesize relationships across thousands of pages of disparate information, revealing insights and maintaining consistency in a way that's impossible with a piecemeal approach.

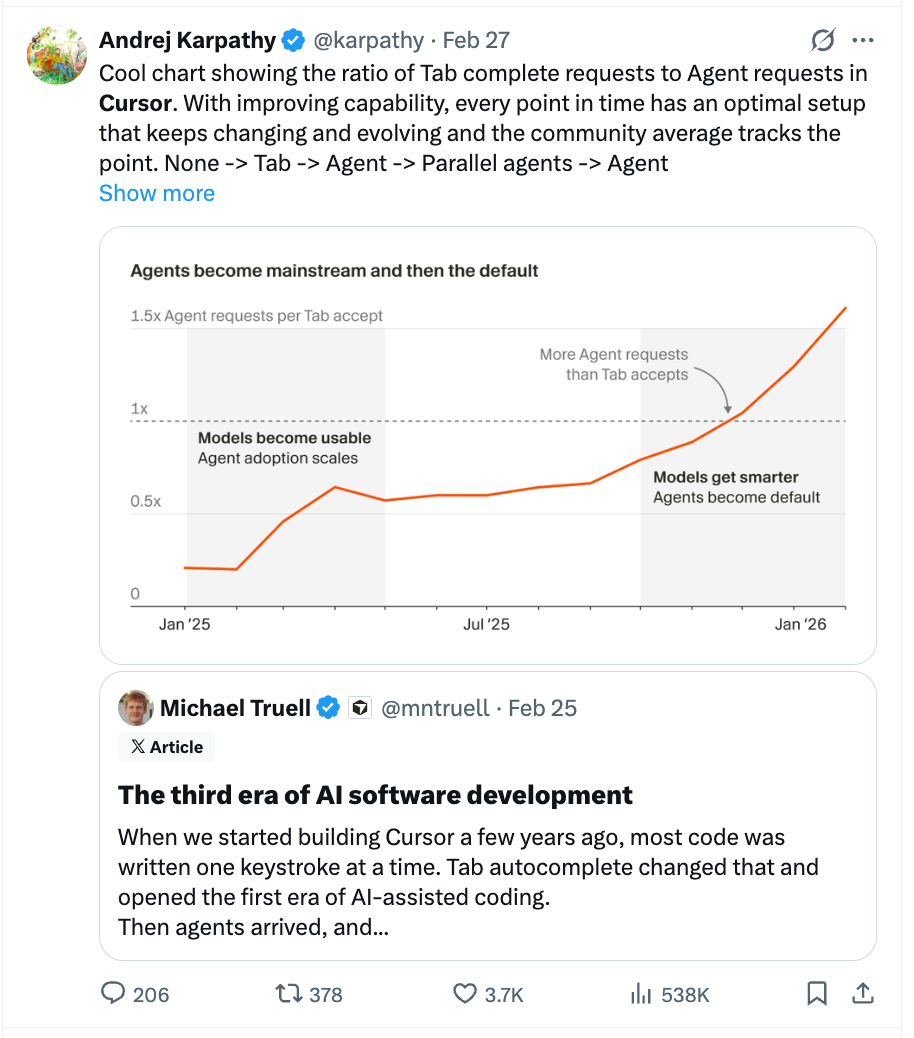
The focus in AI engineering is shifting from making a single agent faster (latency) to running many agents in parallel (throughput). This "wider pipe" approach gets more total work done but will stress-test existing infrastructure like CI/CD, which wasn't built for this volume.
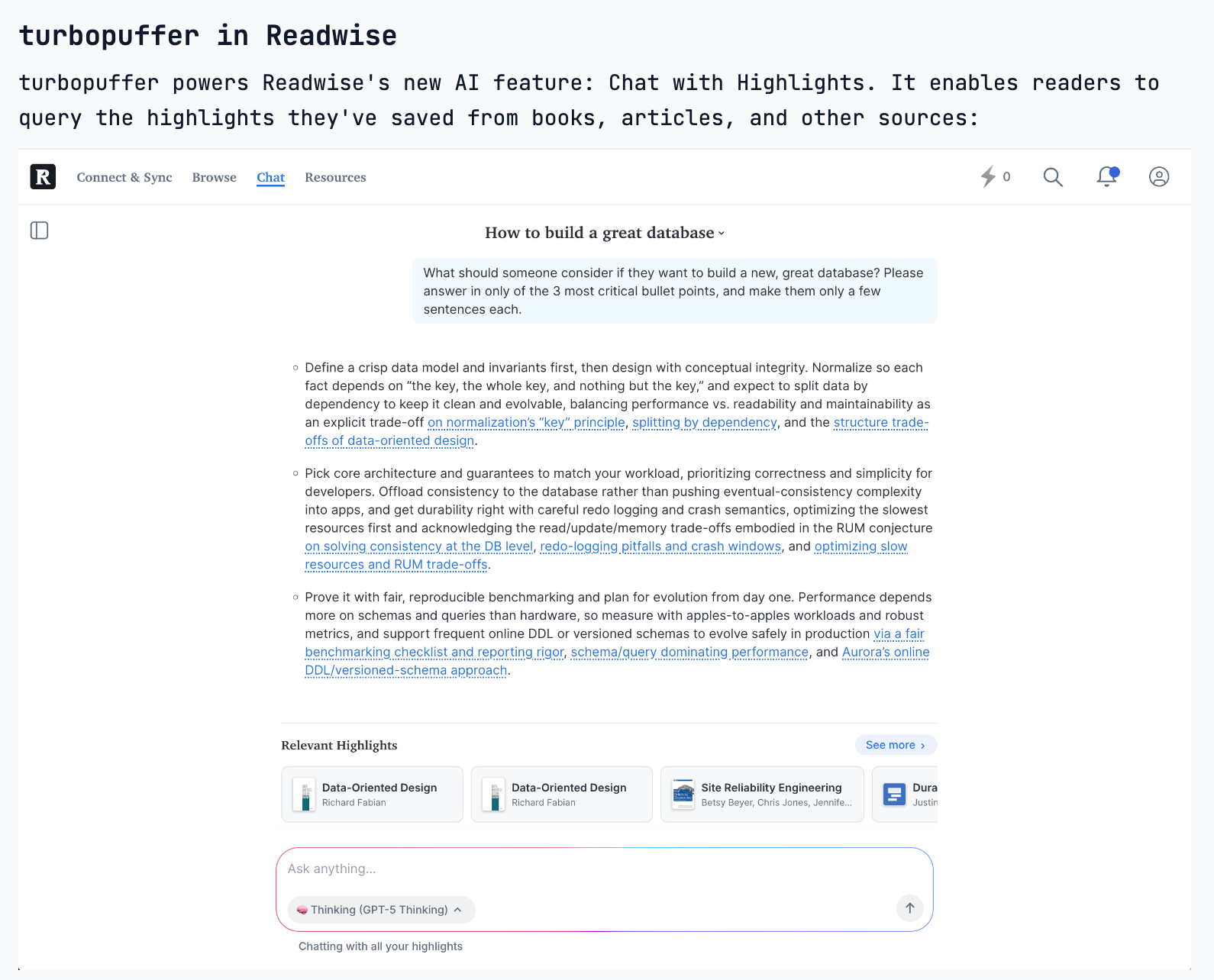
Retrieval Augmented Generation (RAG) uses vector search to find relevant documents based on a user's query. This factual context is then fed to a Large Language Model (LLM), forcing it to generate responses based on provided data, which significantly reduces the risk of "hallucinations."

Teams often agonize over which vector database to use for their Retrieval-Augmented Generation (RAG) system. However, the most significant performance gains come from superior data preparation, such as optimizing chunking strategies, adding contextual metadata, and rewriting documents into a Q&A format.

Instead of just expanding context windows, the next architectural shift is toward models that learn to manage their own context. Inspired by Recursive Language Models (RLMs), these agents will actively retrieve, transform, and store information in a persistent state, enabling more effective long-horizon reasoning.

To solve the problem of MCPs consuming excessive context, advanced AI clients like Cursor are implementing "dynamic tool calling." This uses a RAG-like approach to search for and load only the most relevant tools for a given user query, rather than pre-loading the entire available toolset.

Unlike chatbots that rely solely on their training data, Google's AI acts as a live researcher. For a single user query, the model executes a 'query fanout'—running multiple, targeted background searches to gather, synthesize, and cite fresh information from across the web in real-time.

AEO is not about getting into an LLM's training data, which is slow and difficult. Instead, it focuses on Retrieval-Augmented Generation (RAG)—the process where the LLM performs a live search for current information. This makes AEO a real-time, controllable marketing channel.

The agent development process can be significantly sped up by running multiple tasks concurrently. While one agent is engineering a prompt, other processes can be simultaneously scraping websites for a RAG database and conducting deep research on separate platforms. This parallel workflow is key to building complex systems quickly.

Classic RAG involves a single data retrieval step. Its evolution, "agentic retrieval," allows an AI to perform a series of conditional fetches from different sources (APIs, databases). This enables the handling of complex queries where each step informs the next, mimicking a research process.
