Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
To combat hallucinations and bias, don't rely on a single AI tool. For important decisions, query multiple large language models (e.g., Claude, Gemini) with the same prompt. This "second opinion" approach allows you to compare answers, identify inconsistencies, and blend the best elements for a more reliable outcome.

Related Insights
While guardrails in prompts are useful, a more effective step to prevent AI agents from hallucinating is careful model selection. For instance, using Google's Gemini models, which are noted to hallucinate less, provides a stronger foundational safety layer than relying solely on prompt engineering with more 'creative' models.

Relying on a single model family for generation and review is suboptimal. Blitzy found that using models from different developers (e.g., OpenAI, Anthropic) to check each other's work produces tremendously better results, as each family has distinct strengths and reasoning patterns.

Create a custom Claude Code skill that sends a spec or problem to multiple LLM APIs (e.g., ChatGPT, Gemini, Grok) simultaneously. This "council of AIs" provides diverse feedback, catching errors or omissions that a single model might miss, leading to more robust plans.

Instead of relying on a single AI, use different models (e.g., ChatGPT for internal context, Claude for an objective view) for the same problem. This multi-model approach generates diverse perspectives and higher-quality strategic outputs.

AI expert Andrej Karpathy suggests treating LLMs as simulators, not entities. Instead of asking, "What do you think?", ask, "What would a group of [relevant experts] say?". This elicits a wider range of simulated perspectives and avoids the biases inherent in forcing the LLM to adopt a single, artificial persona.

Different LLMs have unique strengths and knowledge gaps. Instead of relying on one model, an "LLM Council" approach queries multiple models (e.g., Claude, Gemini) for the same prompt and then uses an agent to aggregate and synthesize the responses into one superior output.

To move beyond casual use, serious AI practitioners should use and pay for premium versions of multiple models (e.g., ChatGPT, Claude, Gemini). Each model has a different 'persona' and training, providing a diversity of thought in their outputs that is essential for complex tasks and avoiding vendor lock-in.

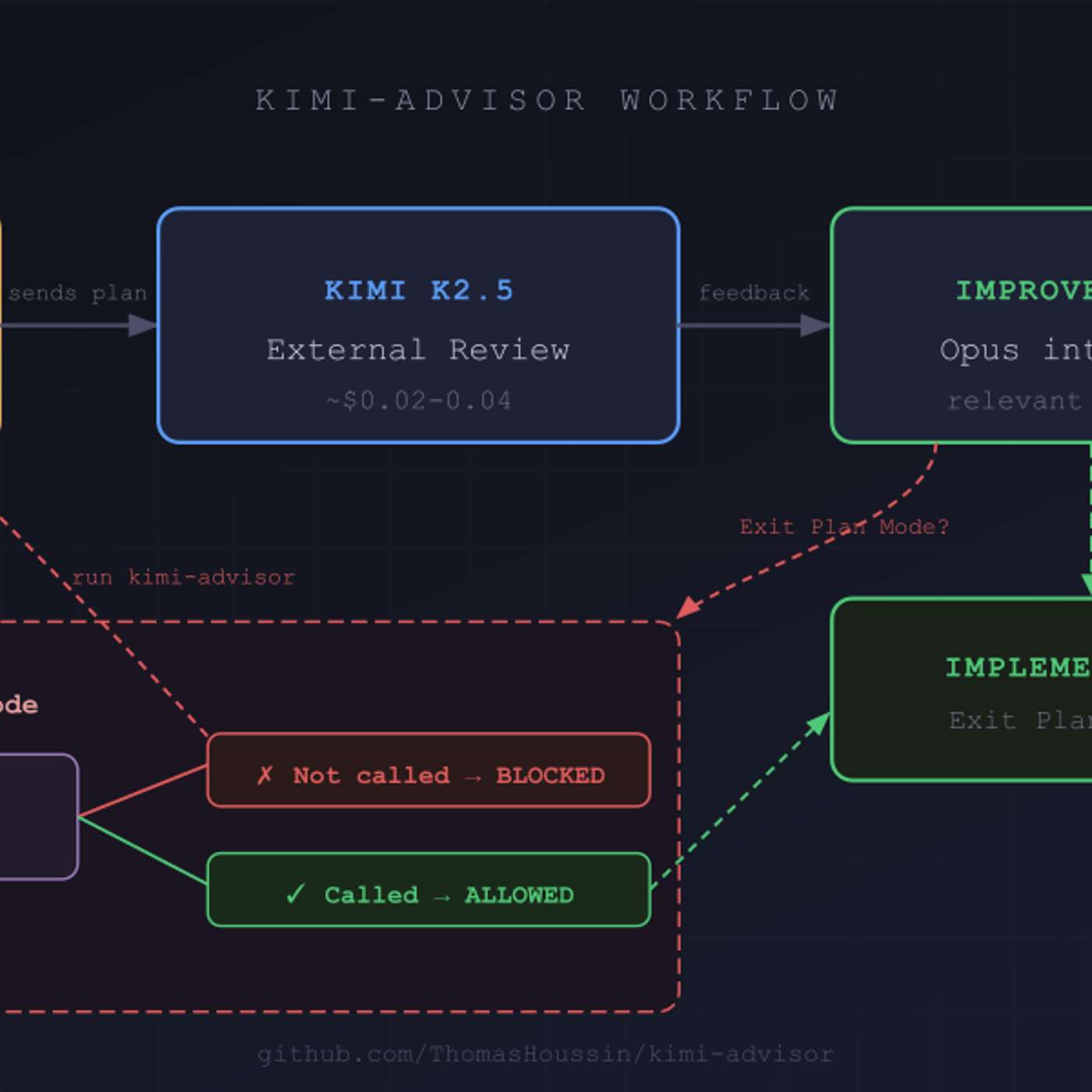
To improve code quality, use a secondary AI model from a different provider (e.g., Moonshot AI's Kimi) to review plans generated by a primary model (e.g., Anthropic's Claude). This introduces cognitive diversity and avoids the shared biases inherent in a single model family, leading to a more robust and enriching review process.
All data inputs for AI are inherently biased (e.g., bullish management, bearish former employees). The most effective approach is not to de-bias the inputs but to use AI to compare and contrast these biased perspectives to form an independent conclusion.

Since true AI explainability is still elusive, a practical strategy for managing risk is benchmarking. By running a new AI model alongside the current one and comparing their outputs on a defined set of tests, companies can identify and address issues like bias or unexpected behavior before a full rollout.
