Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
A comprehensive approach to mitigating AI bias requires addressing three separate components. First, de-bias the training data before it's ingested. Second, audit and correct biases inherent in pre-trained models. Third, implement human-centered feedback loops during deployment to allow the system to self-correct based on real-world usage and outcomes.

Related Insights
Unlike traditional software where problems are solved by debugging code, improving AI systems is an organic process. Getting from an 80% effective prototype to a 99% production-ready system requires a new development loop focused on collecting user feedback and signals to retrain the model.

Treating ethical considerations as a post-launch fix creates massive "technical debt" that is nearly impossible to resolve. Just as an AI trained to detect melanoma on one skin color fails on others, solutions built on biased data are fundamentally flawed. Ethics must be baked into the initial design and data gathering process.

Effective enterprise AI deployment involves running human and AI workflows in parallel. When the AI fails, it generates a data point for fine-tuning. When the human fails, it becomes a training moment for the employee. This "tandem system" creates a continuous feedback loop for both the model and the workforce.

Instead of waiting for AI models to be perfect, design your application from the start to allow for human correction. This pragmatic approach acknowledges AI's inherent uncertainty and allows you to deliver value sooner by leveraging human oversight to handle edge cases.

The core of an effective AI data flywheel is a process that captures human corrections not as simple fixes, but as perfectly formatted training examples. This structured data, containing the original input, the AI's error, and the human's ground truth, becomes a portable, fine-tuning-ready asset that directly improves the next model iteration.

The effectiveness of an AI system isn't solely dependent on the model's sophistication. It's a collaboration between high-quality training data, the model itself, and the contextual understanding of how to apply both to solve a real-world problem. Neglecting data or context leads to poor outcomes.
Shift the view of AI from a singular product launch to a continuous process encompassing use case selection, training, deployment, and decommissioning. This broader aperture creates multiple intervention points to embed responsibility and mitigate harm throughout the lifecycle.

Shift the AI development process by starting with workshops for the people who will live with the system, not just those who pay for it. The primary goal is to translate their stories and needs into tangible checks for fairness and feedback before focusing on technical metrics like accuracy and speed.
Instead of treating a complex AI system like an LLM as a single black box, build it in a componentized way by separating functions like retrieval, analysis, and output. This allows for isolated testing of each part, limiting the surface area for bias and simplifying debugging.
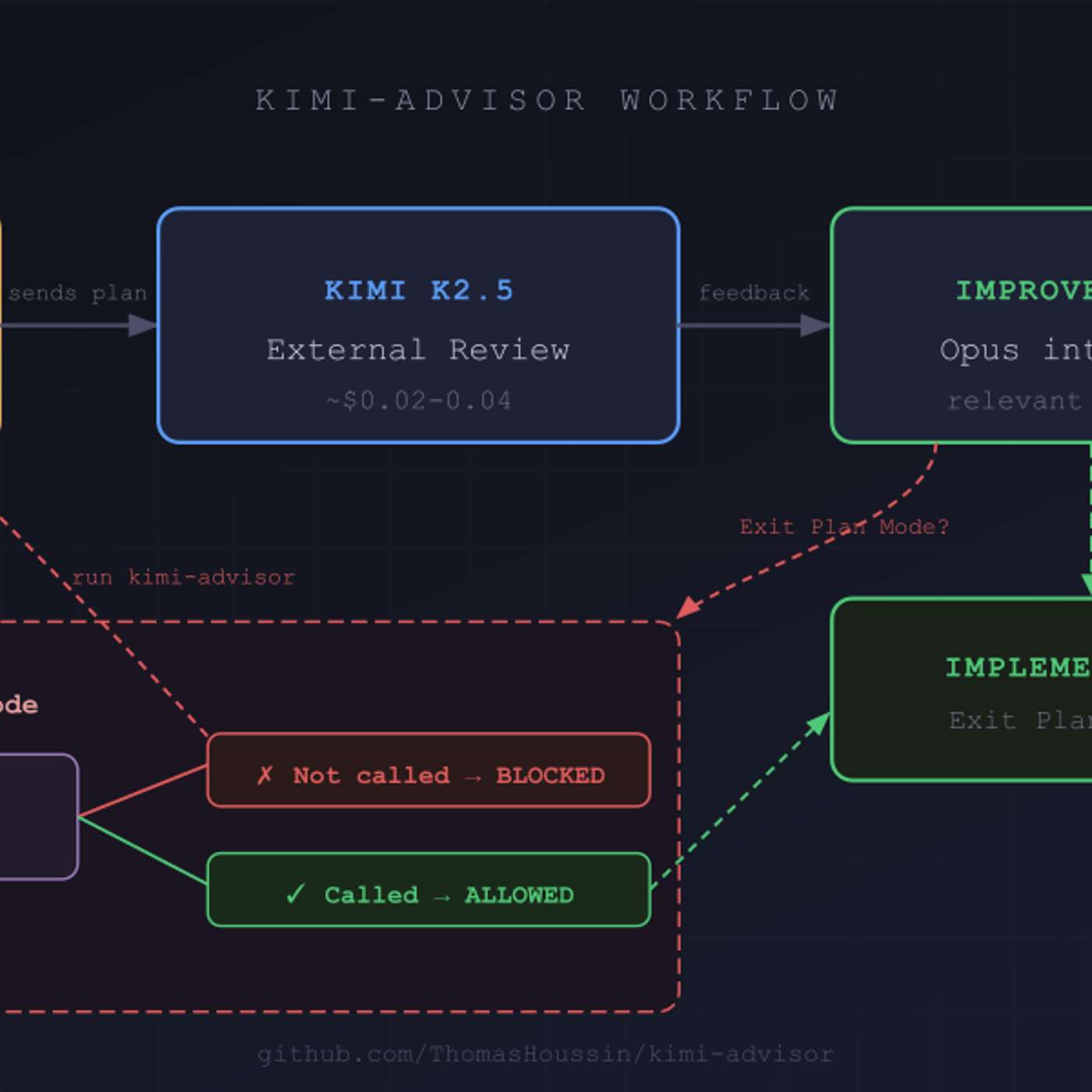
To improve code quality, use a secondary AI model from a different provider (e.g., Moonshot AI's Kimi) to review plans generated by a primary model (e.g., Anthropic's Claude). This introduces cognitive diversity and avoids the shared biases inherent in a single model family, leading to a more robust and enriching review process.