Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
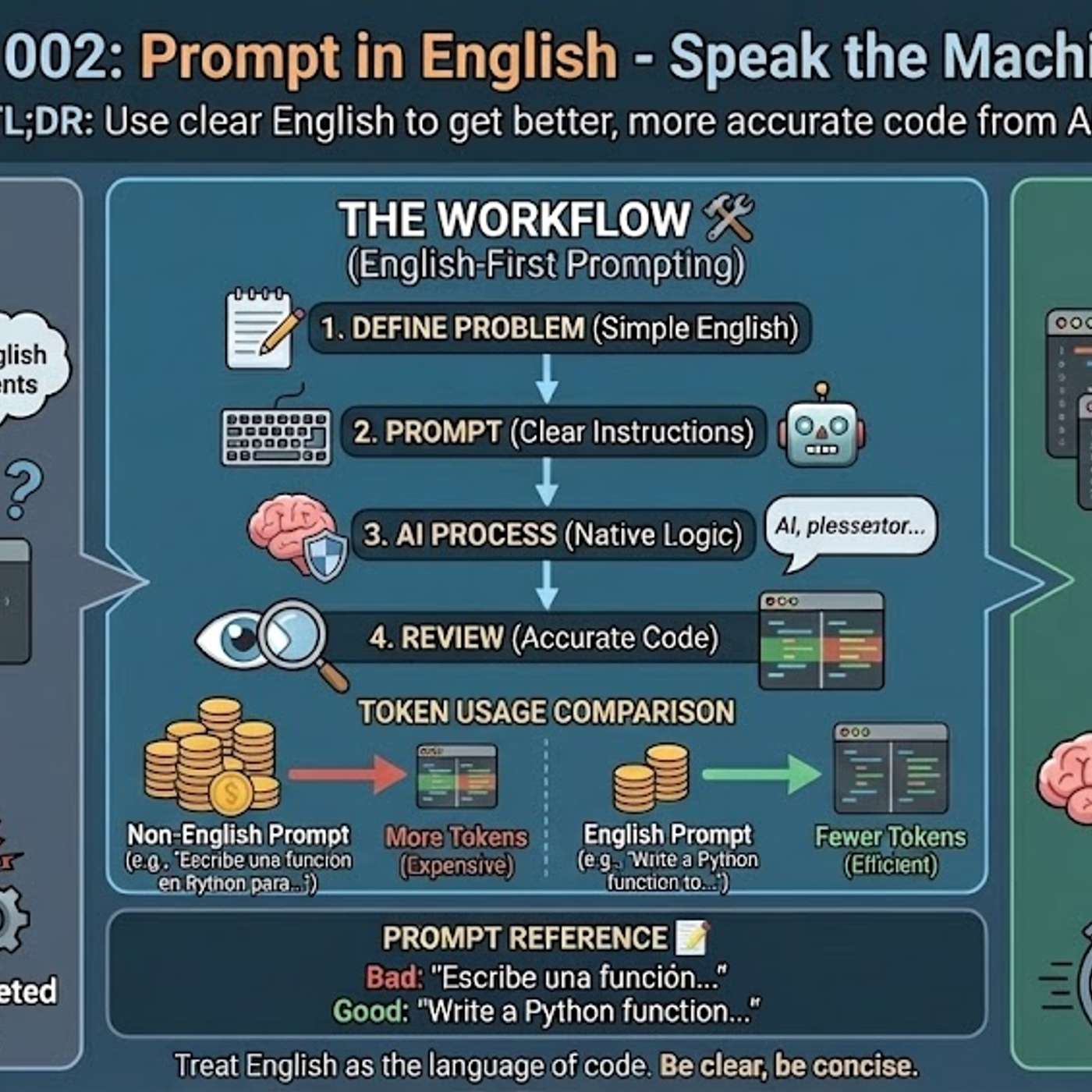
Beyond the obvious lack of non-English training data, Large Language Models are architecturally biased. Their tokenization process, designed for English, inefficiently breaks down other languages into more fragments. This increases operational costs and reduces comprehension, creating a structural disadvantage.

Related Insights
MIT research reveals that large language models develop "spurious correlations" by associating sentence patterns with topics. This cognitive shortcut causes them to give domain-appropriate answers to nonsensical queries if the grammatical structure is familiar, bypassing logical analysis of the actual words.

Using languages other than English for technical prompts is inefficient because it forces the AI to perform an intermediate translation. This translation step consumes valuable tokens from the context window, leaving less capacity for detailed instructions and increasing the risk of misinterpretation, which results in weaker solutions.
While text-based AI models struggle with non-English languages, the problem is exponentially worse for audio models. The lack of diverse, high-quality audio training data (across ages, genders, topics) in various languages is a critical bottleneck for companies aiming for global adoption of audio-first AI.

A unified tokenizer, while efficient, may not be optimal for both understanding and generation tasks. The ideal data representation for one task might differ from the other, potentially creating a performance bottleneck that specialized models would avoid.
Current LLMs abstract language into discrete tokens, losing rich information like font, layout, and spatial arrangement. A "pixel maximalist" view argues that processing visual representations of text (as humans do) is a more lossless, general approach that captures the physical manifestation of language in the world.

Models built for multilingual use, like Meta's LLaMA, don't necessarily "think" in multiple languages. They often retrieve answers internally in English and then translate back to the source language. This extra step introduces significant opportunities for error, undermining their multilingual promise and losing knowledge in translation.
Technical terms like "callback" often lack a precise one-to-one translation in other languages. When a non-English prompt is used, the AI may misinterpret these crucial terms, leading it to misunderstand the user's intent, waste context tokens trying to disambiguate the instruction, and ultimately generate incorrect or suboptimal code.
The binary distinction between "reasoning" and "non-reasoning" models is becoming obsolete. The more critical metric is now "token efficiency"—a model's ability to use more tokens only when a task's difficulty requires it. This dynamic token usage is a key differentiator for cost and performance.

The primary reason AI models generate better code from English prompts is their training data composition. Over 90% of AI training sets, along with most technical libraries and documentation, are in English. This means the models' core reasoning pathways for code-related tasks are fundamentally optimized for English.
Poland's AI lead observes that frontier models like Anthropic's Claude are degrading in their Polish language and cultural abilities. As developers focus on lucrative use cases like coding, they trade off performance in less common languages, creating a major reliability risk for businesses in non-Anglophone regions who depend on these APIs.
