Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
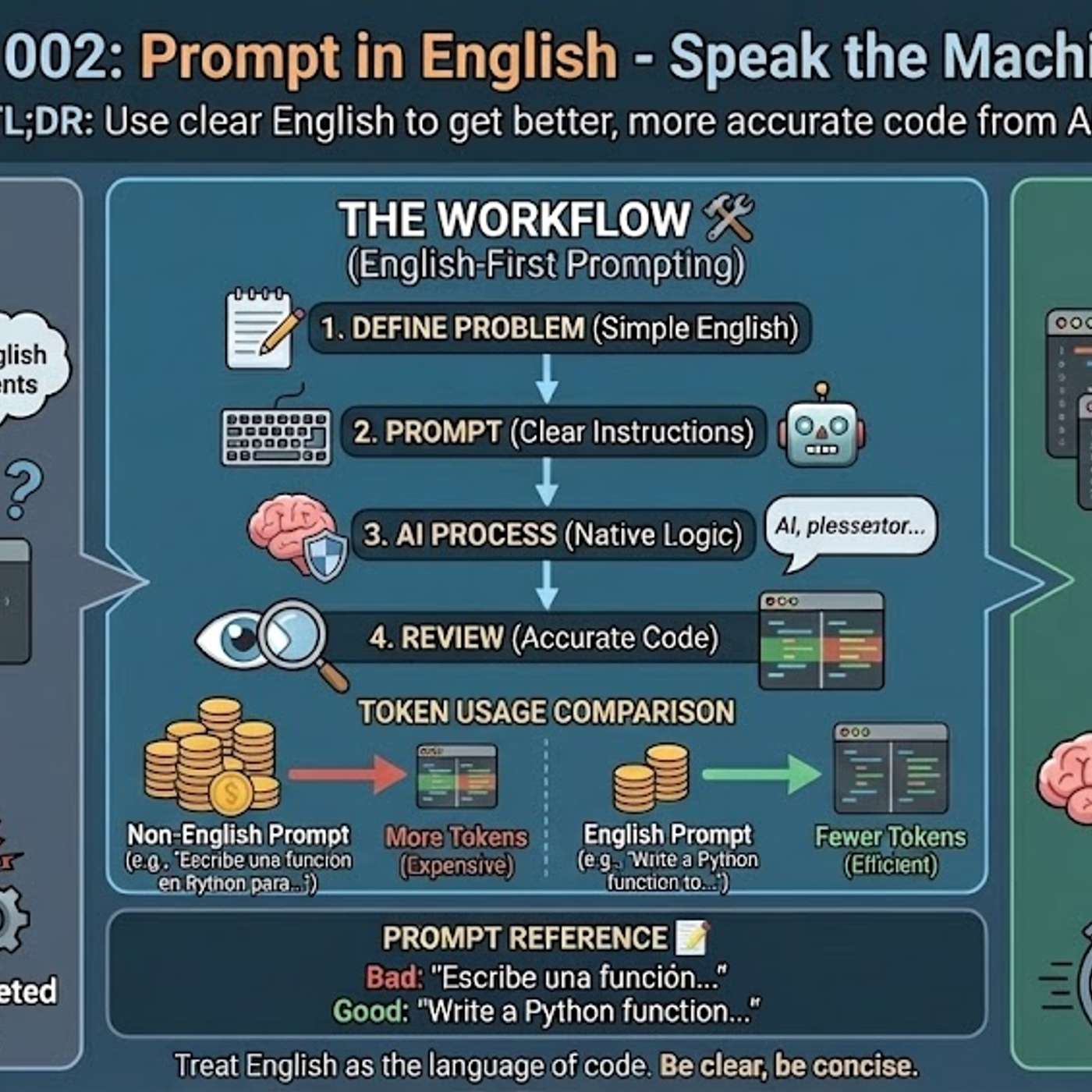
Technical terms like "callback" often lack a precise one-to-one translation in other languages. When a non-English prompt is used, the AI may misinterpret these crucial terms, leading it to misunderstand the user's intent, waste context tokens trying to disambiguate the instruction, and ultimately generate incorrect or suboptimal code.
Related Insights
People struggle with AI prompts because the model lacks background on their goals and progress. The solution is 'Context Engineering': creating an environment where the AI continuously accumulates user-specific information, materials, and intent, reducing the need for constant prompt tweaking.

When using AI development tools, first leverage their "planning" mode. The AI may correctly identify code to change but misinterpret the strategic goal. Correct the AI's plan (e.g., from a global change to a user-specific one) before implementation to avoid rework.
![Building a Personal AI Model Map [AI Operators Bonus Episode] thumbnail](https://d3t3ozftmdmh3i.cloudfront.net/staging/podcast_uploaded_nologo/41472609/41472609-1752234663609-8665756a468e5.jpg)
Using languages other than English for technical prompts is inefficient because it forces the AI to perform an intermediate translation. This translation step consumes valuable tokens from the context window, leaving less capacity for detailed instructions and increasing the risk of misinterpretation, which results in weaker solutions.
A non-obvious failure mode for voice AI is misinterpreting accented English. A user speaking English with a strong Russian accent might find their speech transcribed directly into Russian Cyrillic. This highlights a complex, and frustrating, challenge in building robust and inclusive voice models for a global user base.

Many AI tools expose the model's reasoning before generating an answer. Reading this internal monologue is a powerful debugging technique. It reveals how the AI is interpreting your instructions, allowing you to quickly identify misunderstandings and improve the clarity of your prompts for better results.

Even models with million-token context windows suffer from "context rot" when overloaded with information. Performance degrades as the model struggles to find the signal in the noise. Effective context engineering requires precision, packing the window with only the exact data needed.

A major hurdle in AI adoption is not the technology's capability but the user's inability to prompt effectively. When presented with a natural language interface, many users don't know how to ask for what they want, leading to poor results and abandonment, highlighting the need for prompt guidance.

Poland's AI lab discovered that safety and security measures implemented in models primarily trained and secured for English are much easier to circumvent using Polish prompts. This highlights a critical vulnerability in global AI models and necessitates local, language-specific safety training and red-teaming to create robust safeguards.

The primary reason AI models generate better code from English prompts is their training data composition. Over 90% of AI training sets, along with most technical libraries and documentation, are in English. This means the models' core reasoning pathways for code-related tasks are fundamentally optimized for English.
Poland's AI lead observes that frontier models like Anthropic's Claude are degrading in their Polish language and cultural abilities. As developers focus on lucrative use cases like coding, they trade off performance in less common languages, creating a major reliability risk for businesses in non-Anglophone regions who depend on these APIs.