Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
The primary reason AI models generate better code from English prompts is their training data composition. Over 90% of AI training sets, along with most technical libraries and documentation, are in English. This means the models' core reasoning pathways for code-related tasks are fundamentally optimized for English.
Related Insights
Anthropic's David Hershey states it's "deeply unsurprising" that AI is great at software engineering because the labs are filled with software engineers. This suggests AI's capabilities are skewed by its creators' expertise, and achieving similar performance in fields like law requires deeper integration with domain experts.

LLMs shine when acting as a 'knowledge extruder'—shaping well-documented, 'in-distribution' concepts into specific code. They fail when the core task is novel problem-solving where deep thinking, not code generation, is the bottleneck. In these cases, the code is the easy part.

To increase developer adoption, OpenAI intentionally trained its models on specific behavioral characteristics, not just coding accuracy. These 'personality' traits include communication (explaining its steps), planning, and self-checking, mirroring best practices of human software engineers to make the AI a more trustworthy pair programmer.

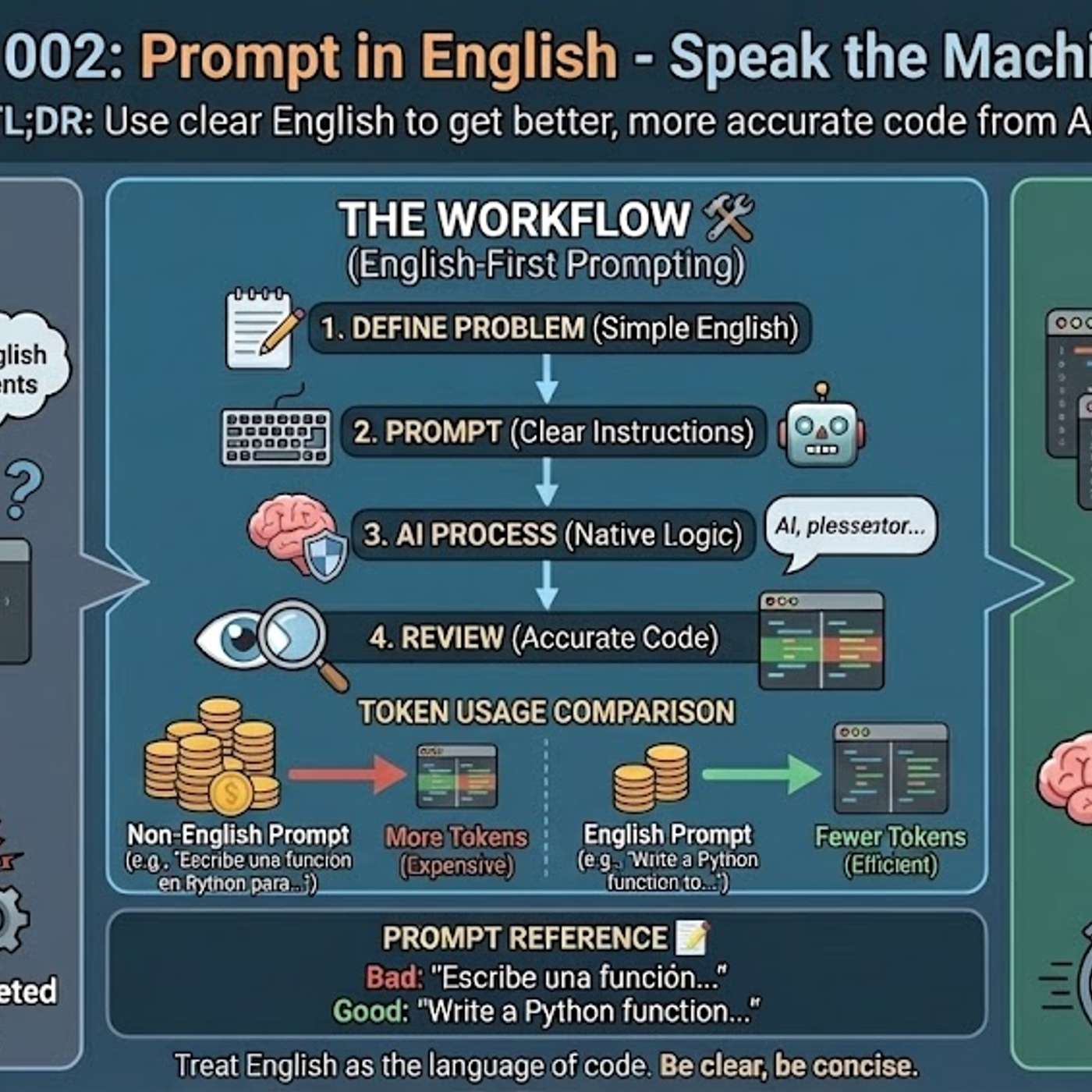
Using languages other than English for technical prompts is inefficient because it forces the AI to perform an intermediate translation. This translation step consumes valuable tokens from the context window, leaving less capacity for detailed instructions and increasing the risk of misinterpretation, which results in weaker solutions.
Despite being a language model, ChatGPT's most valuable application in a data journalism experiment was not reporting or summarizing but its ability to generate and debug Python code for a map. This technical capability proved more efficient and reliable than its core content-related functions.

The initial magic of GitHub's Copilot wasn't its accuracy but its profound understanding of natural language. Early versions had a code completion acceptance rate of only 20%, yet the moments it correctly interpreted human intent were so powerful they signaled a fundamental technology shift.
Poland's AI lab discovered that safety and security measures implemented in models primarily trained and secured for English are much easier to circumvent using Polish prompts. This highlights a critical vulnerability in global AI models and necessitates local, language-specific safety training and red-teaming to create robust safeguards.

Technical terms like "callback" often lack a precise one-to-one translation in other languages. When a non-English prompt is used, the AI may misinterpret these crucial terms, leading it to misunderstand the user's intent, waste context tokens trying to disambiguate the instruction, and ultimately generate incorrect or suboptimal code.
AI development has evolved to where models can be directed using human-like language. Instead of complex prompt engineering or fine-tuning, developers can provide instructions, documentation, and context in plain English to guide the AI's behavior, democratizing access to sophisticated outcomes.

To improve LLM reasoning, researchers feed them data that inherently contains structured logic. Training on computer code was an early breakthrough, as it teaches patterns of reasoning far beyond coding itself. Textbooks are another key source for building smaller, effective models.
