Adopting a single, unified architecture for both vision and generation tasks simplifies the engineering lifecycle. This approach reduces the cost and complexity of maintaining, updating, and deploying multiple specialized models, accelerating development.
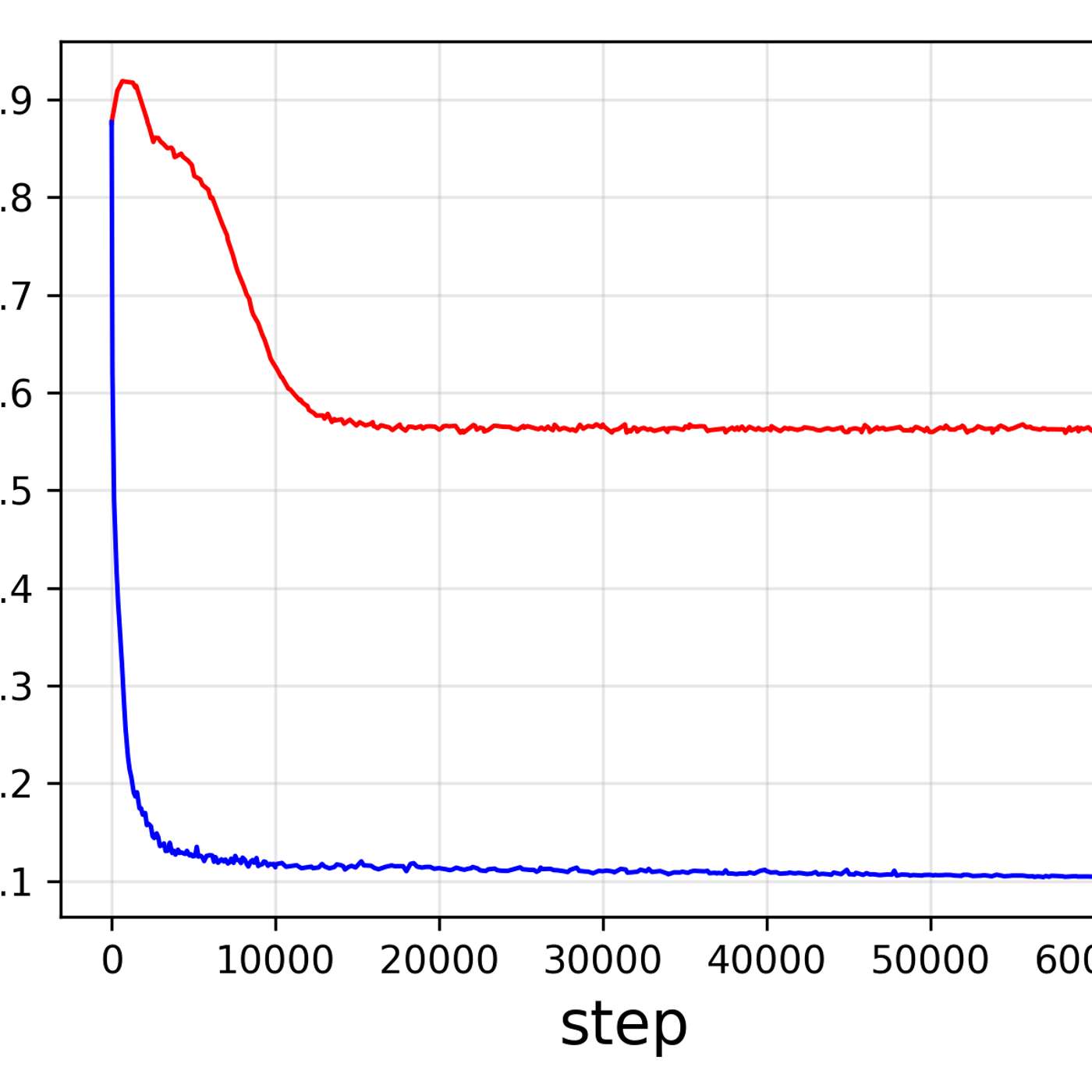
A unified tokenizer, while efficient, may not be optimal for both understanding and generation tasks. The ideal data representation for one task might differ from the other, potentially creating a performance bottleneck that specialized models would avoid.
The ability of a single encoder to excel at both understanding and generating images indicates these two tasks are not as distinct as they seem. It suggests they rely on a shared, fundamental structure of visual information that can be captured in one unified representation.