Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
While text-based AI models struggle with non-English languages, the problem is exponentially worse for audio models. The lack of diverse, high-quality audio training data (across ages, genders, topics) in various languages is a critical bottleneck for companies aiming for global adoption of audio-first AI.

Related Insights
Descript's AI audio tool worsened after they trained it on extremely bad audio (e.g., vacuum cleaners). They learned the model that best fixes terrible audio is different from the one that best improves merely "okay" audio—the more common user scenario. You must train for your primary user's reality, not the worst possible edge case.
Voice-to-voice AI models promise more natural, low-latency conversations by processing audio directly. However, they are currently impractical for many high-stakes enterprise applications due to a hallucination rate that can be eight times higher than text-based systems.
![Jesse Zhang - Building Decagon - [Invest Like the Best, EP.443] thumbnail](https://megaphone.imgix.net/podcasts/2cc4da2a-a266-11f0-ac41-9f5060c6f4ef/image/7df6dc347b875d4b90ae98f397bf1cb1.jpg?ixlib=rails-4.3.1&max-w=3000&max-h=3000&fit=crop&auto=format,compress)
Humane developed a foundational model from scratch trained on proprietary Arabic data. The primary goals were not to compete with global leaders, but to understand cultural nuances, address language biases, and, most importantly, train the internal team on building the entire AI stack from the ground up.

A non-obvious failure mode for voice AI is misinterpreting accented English. A user speaking English with a strong Russian accent might find their speech transcribed directly into Russian Cyrillic. This highlights a complex, and frustrating, challenge in building robust and inclusive voice models for a global user base.

Despite AI's impressive capabilities, it lags significantly behind humans in learning efficiency. Today's models are trained on amounts of data that would take a person tens of thousands of years to consume, while a human child achieves language fluency in under ten years, indicating a fundamental algorithmic difference.

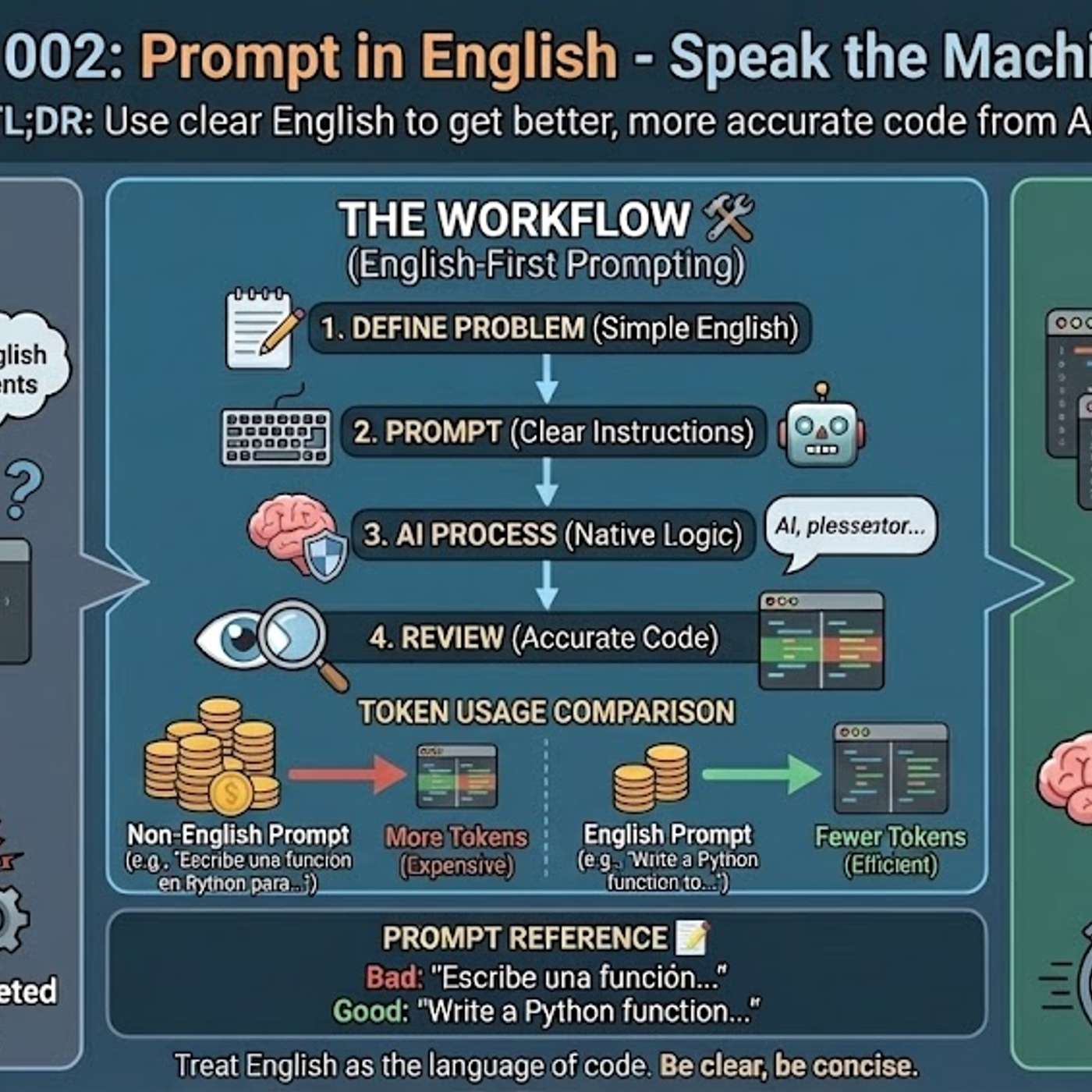
The primary reason AI models generate better code from English prompts is their training data composition. Over 90% of AI training sets, along with most technical libraries and documentation, are in English. This means the models' core reasoning pathways for code-related tasks are fundamentally optimized for English.
Language barriers have historically limited video reach. Meta AI's automatic translation and lip-sync dubbing for Reels allows marketers to seamlessly adapt content for different languages, removing the need for non-verbal videos or expensive localization and opening up new international markets.

Instagram's AI translation goes beyond captions; it dubs audio, alters the speaker's voice, and syncs lip movements to new languages. This allows creators to bypass the language barrier entirely, achieving the global reach previously reserved for silent or universally visual content without requiring additional production effort or cost.
ElevenLabs found that traditional data labelers could transcribe *what* was said but failed to capture *how* it was said (emotion, accent, delivery). The company had to build its own internal team to create this qualitative data layer. This shows that for nuanced AI, especially with unstructured data, proprietary labeling capabilities are a critical, often overlooked, necessity.

Poland's AI lead observes that frontier models like Anthropic's Claude are degrading in their Polish language and cultural abilities. As developers focus on lucrative use cases like coding, they trade off performance in less common languages, creating a major reliability risk for businesses in non-Anglophone regions who depend on these APIs.
