Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Instead of a single "think then act" cycle, Minimax trains its M2 model to repeatedly pause and rethink after receiving feedback from the environment. This iterative "interleaved thinking" approach improves robustness and performance on long-horizon tasks where tool responses or conditions are unpredictable.

Related Insights
Minimax enhances its reinforcement learning process by treating its own expert developers as scalable reward models. These developers participate directly in the training cycle, identifying desirable behaviors and providing precise feedback on complex coding tasks, which creates a model tailored to professional workflows.
While letting a robot 'think' longer improves decision accuracy in lab tests, this added latency poses a significant risk in the real world. If the environment changes during the robot's reasoning period, its final decision may be outdated and dangerous, questioning its practical deployability.
Purely agentic systems can be unpredictable. A hybrid approach, like OpenAI's Deep Research forcing a clarifying question, inserts a deterministic workflow step (a "speed bump") before unleashing the agent. This mitigates risk, reduces errors, and ensures alignment before costly computation.

Progress in complex, long-running agentic tasks is better measured by tokens consumed rather than raw time. Improving token efficiency, as seen from GPT-5 to 5.1, directly enables more tool calls and actions within a feasible operational budget, unlocking greater capabilities.
![[State of Post-Training] From GPT-4.1 to 5.1: RLVR, Agent & Token Efficiency — Josh McGrath, OpenAI thumbnail](https://assets.flightcast.com/V2Uploads/nvaja2542wefzb8rjg5f519m/01K4D8FB4MNA071BM5ZDSMH34N/square.jpg)
Beyond supervised fine-tuning (SFT) and human feedback (RLHF), reinforcement learning (RL) in simulated environments is the next evolution. These "playgrounds" teach models to handle messy, multi-step, real-world tasks where current models often fail catastrophically.

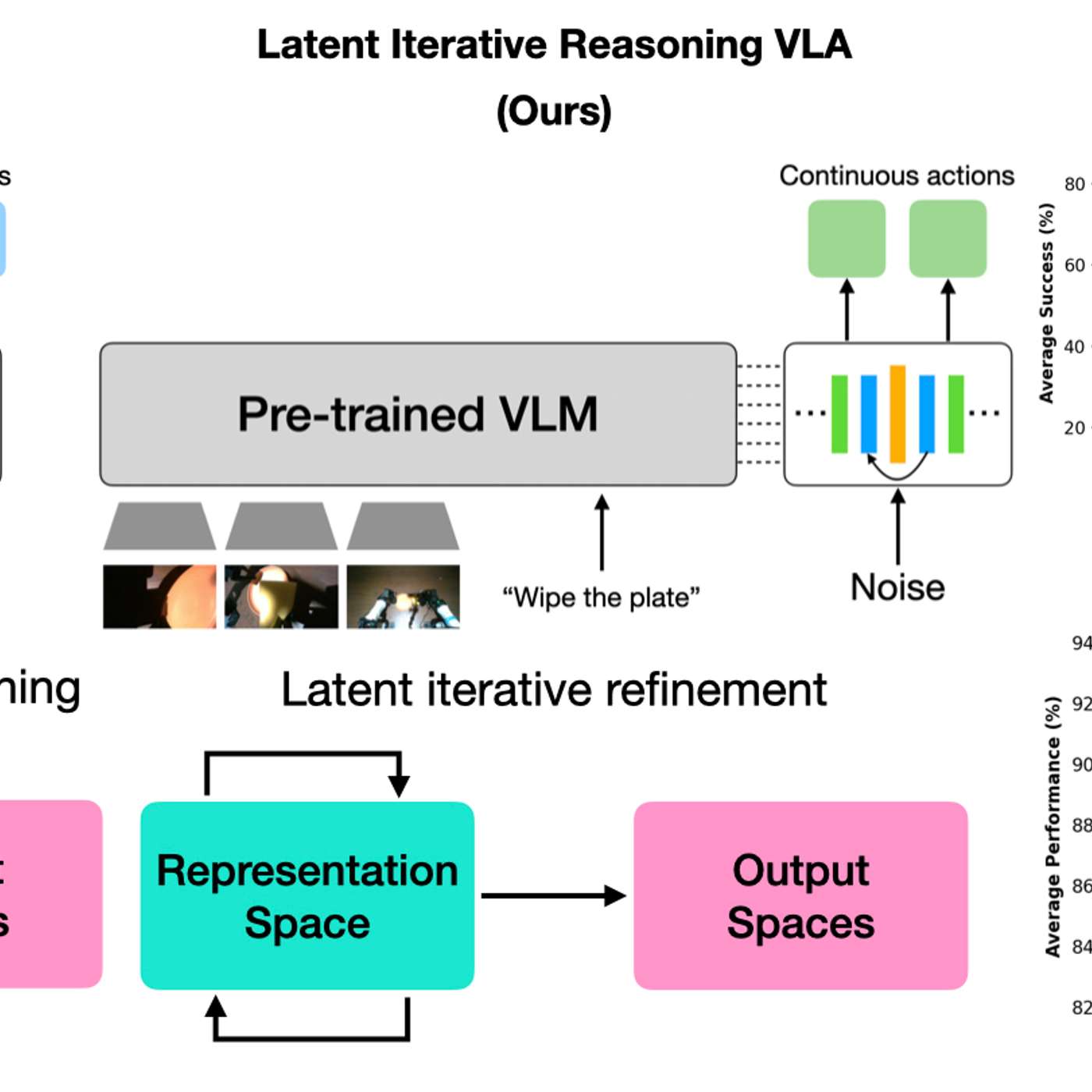
A new model architecture allows robots to vary their internal 'thinking' iterations at test time. This lets practitioners trade response speed for decision accuracy on a case-by-case basis, boosting performance on complex tasks without needing to retrain the model.
The AI's ability to handle novel situations isn't just an emergent property of scale. Waive actively trains "world models," which are internal generative simulators. This enables the AI to reason about what might happen next, leading to sophisticated behaviors like nudging into intersections or slowing in fog.

To avoid context drift in long AI sessions, create temporary, task-based agents with specialized roles. Use these agents as checkpoints to review outputs from previous steps and make key decisions, ensuring higher-quality results and preventing error propagation.

When AI agents communicate on platforms like Maltbook, they create a feedback loop where one agent's output prompts another. This 'middle-to-middle' interaction, without direct human prompting for each step, allows for emergent behavior and a powerful, recursive cycle of improvement and learning.

Minimax discovered that robust AI agent generalization comes from systematically varying the model's entire operational environment—including system prompts, chat templates, and tool responses—not just by increasing the number of tools it's trained on. They use a dedicated perturbation pipeline to ensure this variance.