Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
The rapid, step-change improvements in LLMs are likely slowing down. This is because models have already been trained on most of the available internet, and the compute budget required for each incremental improvement is increasing exponentially to an unsustainable degree. A new architectural breakthrough, not just more data and compute, is needed for the next leap.

Related Insights
The dramatic improvements from GPT-2 to GPT-4 were driven by a simple law: bigger models and more training data yielded better results. This trend has stopped. Recent attempts to scale even larger models have produced only marginal gains, forcing the industry into more complex, narrow optimizations instead of giant leaps.

The relationship between computing power and AI model capability is not linear. According to established 'scaling laws,' a tenfold increase in the compute used for training large language models (LLMs) results in roughly a doubling of the model's capabilities, highlighting the immense resources required for incremental progress.

The era of advancing AI simply by scaling pre-training is ending due to data limits. The field is re-entering a research-heavy phase focused on novel, more efficient training paradigms beyond just adding more compute to existing recipes. The bottleneck is shifting from resources back to ideas.

The sudden arrival of powerful AI like GPT-3 was a non-repeatable event: training on the entire internet and all existing books. With this data now fully "eaten," future advancements will feel more incremental, relying on the slower process of generating new, high-quality expert data.

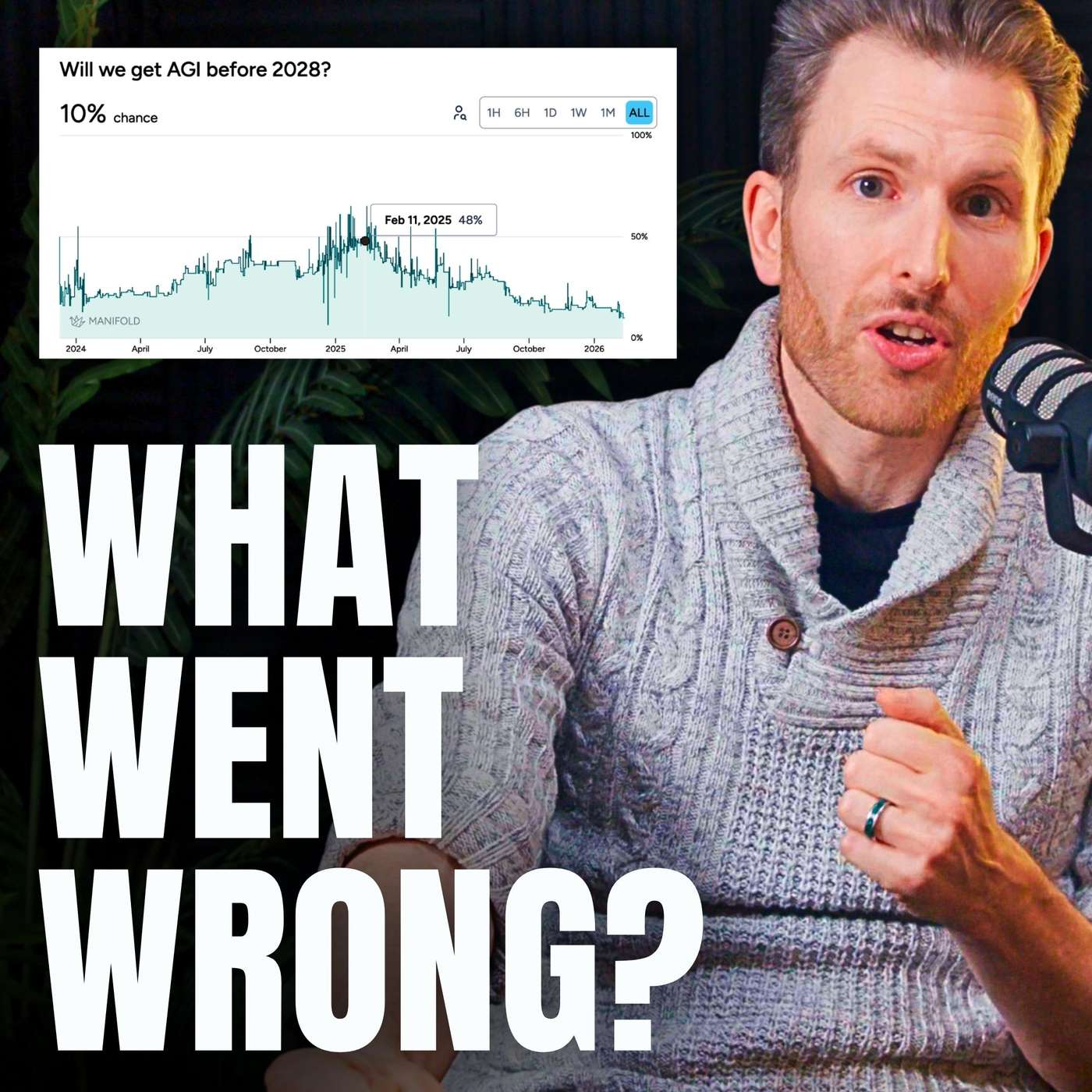
For the first time in years, the perceived leap in LLM capabilities has slowed. While models have improved, the cost increase (from $20 to $200/month for top-tier access) is not matched by a proportional increase in practical utility, suggesting a potential plateau or diminishing returns.

Over two-thirds of reasoning models' performance gains came from massively increasing their 'thinking time' (inference scaling). This was a one-time jump from a zero baseline. Further gains are prohibitively expensive due to compute limitations, meaning this is not a repeatable source of progress.
The plateauing performance-per-watt of GPUs suggests that simply scaling current matrix multiplication-heavy architectures is unsustainable. This hardware limitation may necessitate research into new computational primitives and neural network designs built for large-scale distributed systems, not single devices.

The era of guaranteed progress by simply scaling up compute and data for pre-training is ending. With massive compute now available, the bottleneck is no longer resources but fundamental ideas. The AI field is re-entering a period where novel research, not just scaling existing recipes, will drive the next breakthroughs.

Contrary to the prevailing 'scaling laws' narrative, leaders at Z.AI believe that simply adding more data and compute to current Transformer architectures yields diminishing returns. They operate under the conviction that a fundamental performance 'wall' exists, necessitating research into new architectures for the next leap in capability.

Replit's CEO argues that today's LLMs are asymptoting on general reasoning tasks. Progress continues only in domains with binary outcomes, like coding, where synthetic data can be generated infinitely. This indicates a fundamental limitation of the current 'ingest the internet' approach for achieving AGI.
