Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Over two-thirds of reasoning models' performance gains came from massively increasing their 'thinking time' (inference scaling). This was a one-time jump from a zero baseline. Further gains are prohibitively expensive due to compute limitations, meaning this is not a repeatable source of progress.
Related Insights
A 10x increase in compute may only yield a one-tier improvement in model performance. This appears inefficient but can be the difference between a useless "6-year-old" intelligence and a highly valuable "16-year-old" intelligence, unlocking entirely new economic applications.
![Dylan Patel - Inside the Trillion-Dollar AI Buildout - [Invest Like the Best, EP.442] thumbnail](https://megaphone.imgix.net/podcasts/799253cc-9de9-11f0-8661-ab7b8e3cb4c1/image/d41d3a6f422989dc957ef10da7ad4551.jpg?ixlib=rails-4.3.1&max-w=3000&max-h=3000&fit=crop&auto=format,compress)
Models that generate "chain-of-thought" text before providing an answer are powerful but slow and computationally expensive. For tuned business workflows, the latency from waiting for these extra reasoning tokens is a major, often overlooked, drawback that impacts user experience and increases costs.

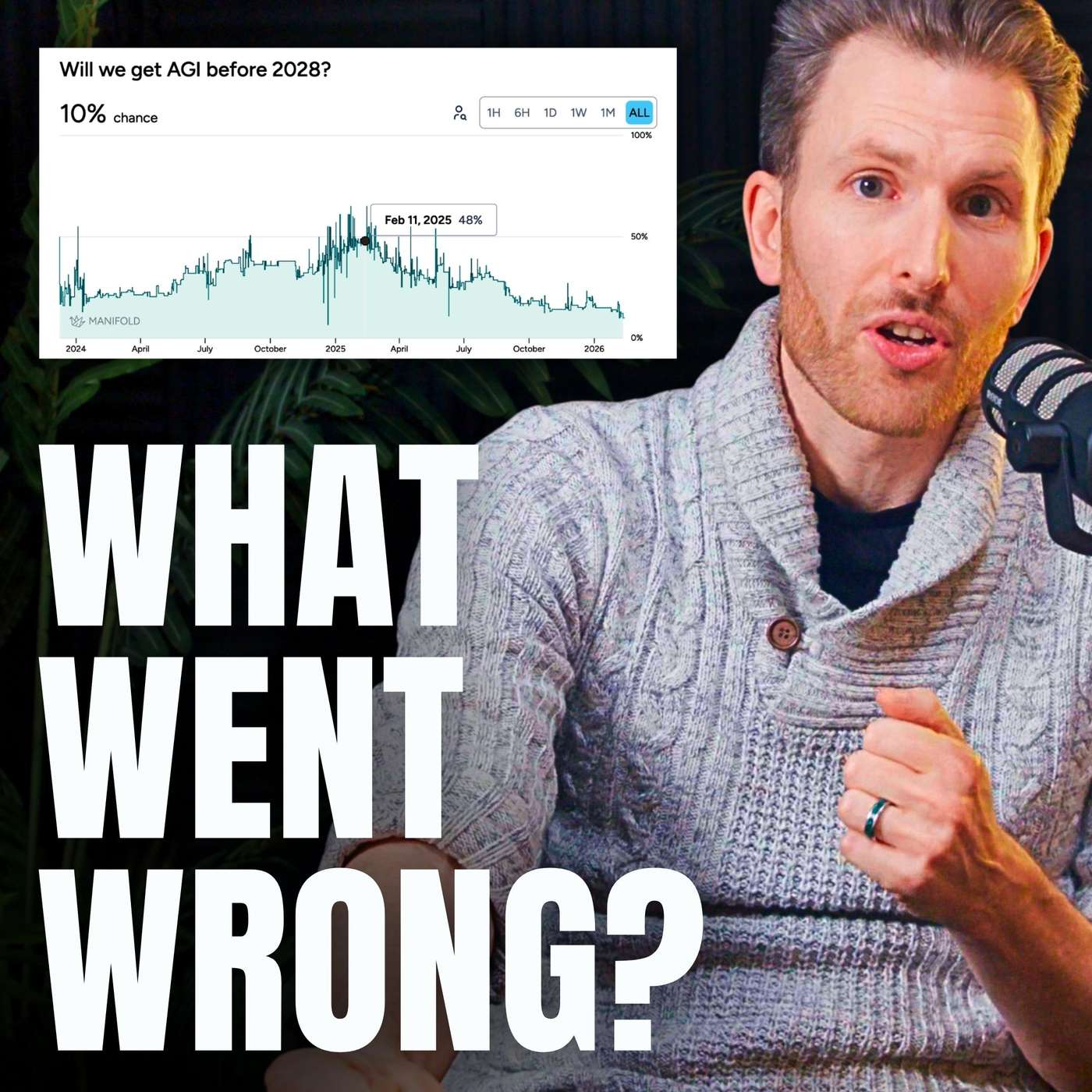
For the first time in years, the perceived leap in LLM capabilities has slowed. While models have improved, the cost increase (from $20 to $200/month for top-tier access) is not matched by a proportional increase in practical utility, suggesting a potential plateau or diminishing returns.

The "bitter lesson" in AI research posits that methods leveraging massive computation scale better and ultimately win out over approaches that rely on human-designed domain knowledge or clever shortcuts, favoring scale over ingenuity.

Broad improvements in AI's general reasoning are plateauing due to data saturation. The next major phase is vertical specialization. We will see an "explosion" of different models becoming superhuman in highly specific domains like chemistry or physics, rather than one model getting slightly better at everything.

The era of guaranteed progress by simply scaling up compute and data for pre-training is ending. With massive compute now available, the bottleneck is no longer resources but fundamental ideas. The AI field is re-entering a period where novel research, not just scaling existing recipes, will drive the next breakthroughs.

Benchmarking reasoning models revealed no clear correlation between the level of reasoning and an LLM's performance. In fact, even when there is a slight accuracy gain (1-2%), it often comes with a significant cost increase, making it an inefficient trade-off.

AI progress was expected to stall in 2024-2025 due to hardware limitations on pre-training scaling laws. However, breakthroughs in post-training techniques like reasoning and test-time compute provided a new vector for improvement, bridging the gap until next-generation chips like NVIDIA's Blackwell arrived.
![Gavin Baker - Nvidia v. Google, Scaling Laws, and the Economics of AI - [Invest Like the Best, EP.451] thumbnail](https://megaphone.imgix.net/podcasts/d97fee14-d4d7-11f0-8951-8324b640c1c1/image/d3a8b5ecbf3957de5b91f278a191c9ff.jpg?ixlib=rails-4.3.1&max-w=3000&max-h=3000&fit=crop&auto=format,compress)
Contrary to the idea that infrastructure problems get commoditized, AI inference is growing more complex. This is driven by three factors: (1) increasing model scale (multi-trillion parameters), (2) greater diversity in model architectures and hardware, and (3) the shift to agentic systems that require managing long-lived, unpredictable state.
While the cost to achieve a fixed capability level (e.g., GPT-4 at launch) has dropped over 100x, overall enterprise spending is increasing. This paradox is explained by powerful multipliers: demand for frontier models, longer reasoning chains, and multi-step agentic workflows that consume exponentially more tokens.
