Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Integrating the latest foundation model is complex because new models can break prompt tuning built around the quirks of older versions. Serval has found that a new model's unpredictability can outweigh its intelligence, sometimes forcing them to downgrade to an older, more reliable model to ensure consistent behavior.

Related Insights
The author observed a "subjective feeling" that older versions of commercial AI models begin to perform worse ("get dumber") immediately preceding the launch of a new version. This suggests that model performance is not static and may be influenced by the provider's release cycle, creating unpredictable results for developers.

While a multi-model approach—using the best AI for each specific task—is theoretically optimal, its practical implementation is difficult. A major roadblock is the need to create and maintain different optimized prompts for each model. This overhead leads users to default to a single, powerful model for simplicity.

Contrary to the assumption that newer is always better, an accounting-specific benchmark found performance regressions in major AI models. This indicates that general improvements don't always translate to specialized domains, requiring companies to rigorously test each new model version for their specific, high-stakes use case.

The true building block of an AI feature is the "agent"—a combination of the model, system prompts, tool descriptions, and feedback loops. Swapping an LLM is not a simple drop-in replacement; it breaks the agent's behavior and requires re-engineering the entire system around it.

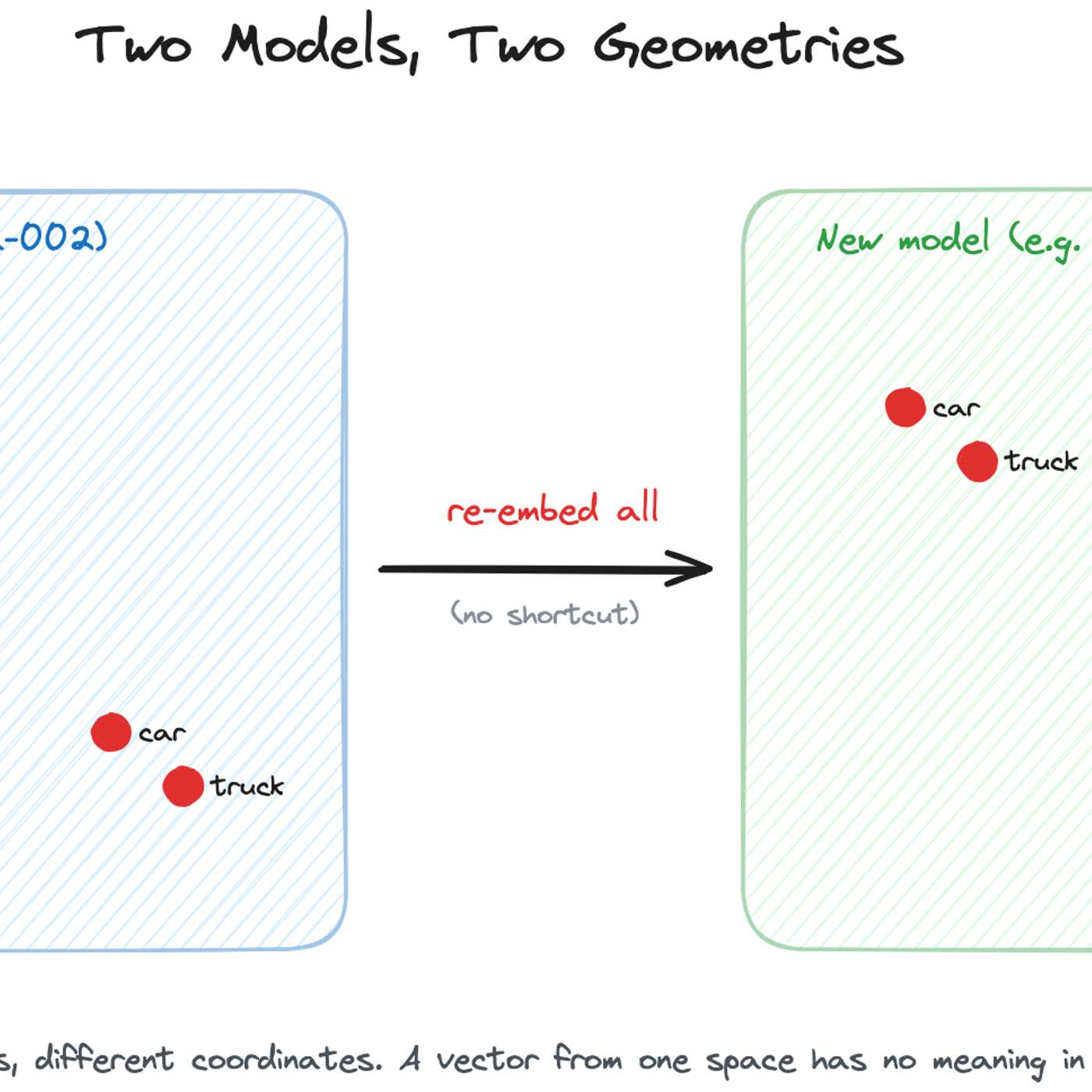
To avoid frantic, high-pressure migrations when an embedding model is deprecated, teams should treat model selection as a dependency that requires planned updates, like any other software library. This mindset shifts the process from an emergency scramble to routine, planned maintenance, making upgrades predictable and manageable.
Unlike traditional APIs, LLMs are hard to abstract away. Users develop a preference for a specific model's 'personality' and performance (e.g., GPT-4 vs. 3.5), making it difficult for applications to swap out the underlying model without user notice and pushback.

When AI labs release new models, they may de-prioritize certain skills like writing to focus on others like agentic capabilities. This causes noticeable shifts in tone and quality, forcing users to re-evaluate and adjust their custom instructions for GPTs and other AI tools.

LLMs in production don't often crash spectacularly. Instead, they introduce subtle, probabilistic errors—like incorrect enum values or missing fields—that are hard to debug because they lack clear error patterns, unlike deterministic code failures.
An AI tool's quality is now almost entirely dependent on its underlying model. The guest notes that 'Windsor', a top-tier agent just three weeks prior, dropped to 'C-tier' simply because it hadn't integrated Claude 4, highlighting the brutal pace of innovation.

Despite constant new model releases, enterprises don't frequently switch LLMs. Prompts and workflows become highly optimized for a specific model's behavior, creating significant switching costs. Performance gains of a new model must be substantial to justify this re-engineering effort.
