Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
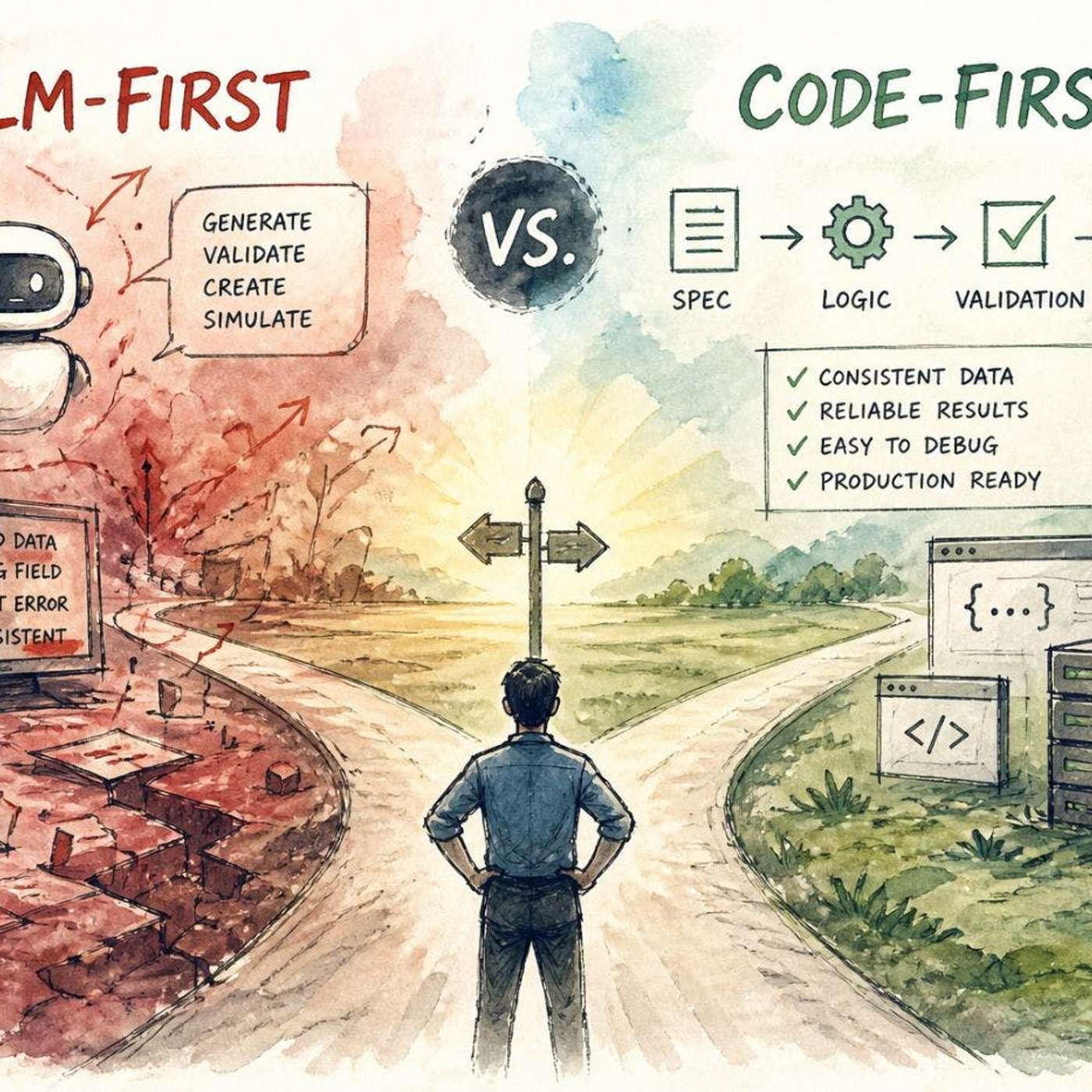
LLMs in production don't often crash spectacularly. Instead, they introduce subtle, probabilistic errors—like incorrect enum values or missing fields—that are hard to debug because they lack clear error patterns, unlike deterministic code failures.
Related Insights
Advanced AI coding tools rarely make basic syntax errors. Their mistakes have evolved to be more subtle and conceptual, akin to those a hasty junior developer might make. They often make incorrect assumptions on the user's behalf and proceed without verification, requiring careful human oversight.

Salesforce's AI Chief warns of "jagged intelligence," where LLMs can perform brilliant, complex tasks but fail at simple common-sense ones. This inconsistency is a significant business risk, as a failure in a basic but crucial task (e.g., loan calculation) can have severe consequences.

An AI agent's failure on a complex task like tax preparation isn't due to a lack of intelligence. Instead, it's often blocked by a single, unpredictable "tiny thing," such as misinterpreting two boxes on a W4 form. This highlights that reliability challenges are granular and not always intuitive.

Despite advancing capabilities, AI models like ChatGPT can exhibit surprising fragility. They can get stuck in nonsensical loops or "spiral out" on straightforward queries, such as questions about Zapier integrations. This unpredictable fallibility demonstrates that model reliability remains a significant challenge, eroding user trust for critical tasks.

Building features like custom commands and sub-agents can look like reliable, deterministic workflows. However, because they are built on non-deterministic LLMs, they fail unpredictably. This misleads users into trusting a fragile abstraction and ultimately results in a poor experience.

AI can generate code that passes initial tests and QA but contains subtle, critical flaws like inverted boolean checks. This creates 'trust debt,' where the system seems reliable but harbors hidden failures. These latent bugs are costly and time-consuming to debug post-launch, eroding confidence in the codebase.

LLMs are technically non-deterministic systems designed to guess the next most probable word, not verify facts like a calculator. This inherent design means they will confidently produce incorrect information, making human verification indispensable for high-stakes business decisions.

Many product builders overestimate current AI capabilities. Understanding AI's limitations, like the non-deterministic nature of LLMs, is more critical than knowing its strengths. Overstating AI's capacity is a direct path to product failure and bad investments.

When selecting foundational models, engineering teams often prioritize "taste" and predictable failure patterns over raw performance. A model that fails slightly more often but in a consistent, understandable way is more valuable and easier to build robust systems around than a top-performer with erratic, hard-to-debug errors.

Setting an LLM's temperature to zero should make its output deterministic, but it doesn't in practice. This is because floating-point number additions, when parallelized across GPUs, are non-associative. The order in which batched operations complete creates tiny variations, preventing true determinism.
