Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
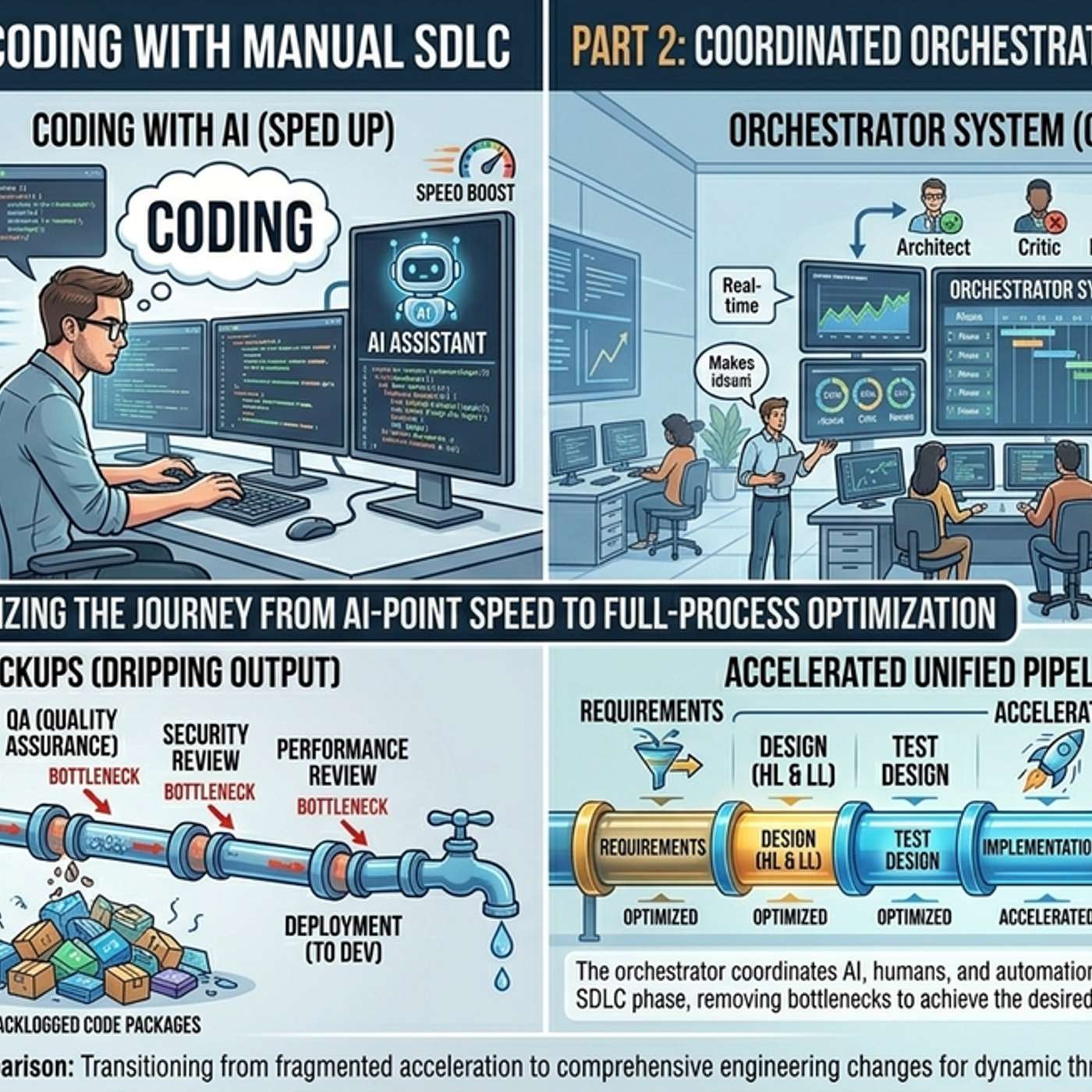
Breaking down the software development lifecycle into small, well-defined subtasks is not just for improving AI success rates. It creates a significant cost-saving opportunity by allowing teams to use cheaper, specialized AI models for most steps, reserving expensive frontier models only for high-complexity tasks like architectural design.
Related Insights
Significant opportunity exists in re-architecting how AI models work. Instead of building ever-larger single models, the focus is shifting to creating networks of smaller, specialized models that collaborate, which can drastically reduce the cost per token produced.
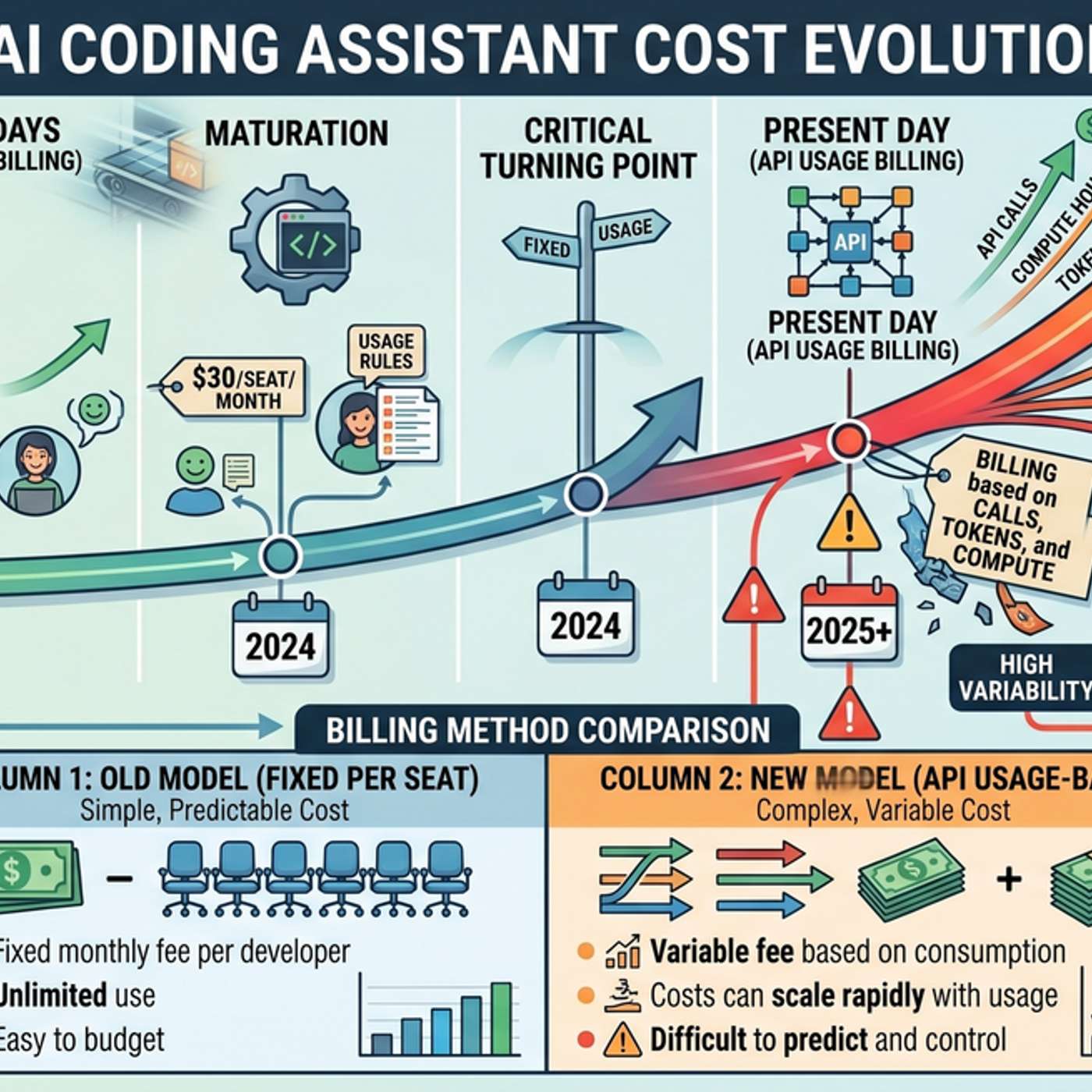
Organizations with structured SDLCs can adapt to consumption-based AI pricing because they can attribute costs to specific work items and make deliberate trade-offs, like routing simple tasks to cheaper models. Teams with ad-hoc workflows will struggle, as unattributable costs spiral and quality becomes inconsistent.
A common pattern for developers building with generative media is to use two types of models. A cheaper, lower-quality 'workhorse' model is used for high-volume tasks like prototyping. A second, expensive, state-of-the-art 'hero' model is then reserved for the final, high-quality output, optimizing for cost and quality.

Don't use your most powerful and expensive AI model for every task. A crucial skill is model triage: using cheaper models for simple, routine tasks like monitoring and scheduling, while saving premium models for complex reasoning, judgment, and creative work.

High productivity isn't about using AI for everything. It's a disciplined workflow: breaking a task into sub-problems, using an LLM for high-leverage parts like scaffolding and tests, and reserving human focus for the core implementation. This avoids the sunk cost of forcing AI on unsuitable tasks.

The path to robust AI applications isn't a single, all-powerful model. It's a system of specialized "sub-agents," each handling a narrow task like context retrieval or debugging. This architecture allows for using smaller, faster, fine-tuned models for each task, improving overall system performance and efficiency.

An effective cost-saving strategy for agentic workflows is to use a powerful model like Claude Opus to perform a complex task once and generate a detailed 'skill.' This skill can then be reliably executed by a much cheaper and faster model like Sonnet for subsequent use.

As enterprises scale AI, the high inference costs of frontier models become prohibitive. The strategic trend is to use large models for novel tasks, then shift 90% of recurring, common workloads to specialized, cost-effective Small Language Models (SLMs). This architectural shift dramatically improves both speed and cost.

To optimize AI costs in development, use powerful, expensive models for creative and strategic tasks like architecture and research. Once a solid plan is established, delegate the step-by-step code execution to less powerful, more affordable models that excel at following instructions.

The trend toward specialized AI models is driven by economics, not just performance. A single, monolithic model trained to be an expert in everything would be massive and prohibitively expensive to run continuously for a specific task. Specialization keeps models smaller and more cost-effective for scaled deployment.
