Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
The agent that writes code is biased and may miss its own errors. Kun Chen uses a tool spawning a new agent with a fresh context. This 'reviewer' agent analyzes the original intent and scrutinizes the code for bugs, catching far more edge cases than self-review.

Related Insights
To get an objective critique of AI-generated content, use a dedicated 'reviewer' sub-agent. This separates the drafting and evaluation processes, preventing the original agent from being biased by its own creation and ensuring a higher quality output.
By programming one AI agent with a skeptical persona to question strategy and check details, the overall quality and rigor of the entire multi-agent system increases, mirroring the effect of a critical thinker in a human team.

Instead of relying on a single AI model, Josh Pigford's workflow uses Opus for initial code generation and then runs a review pass with a different powerful model like GPT. This adversarial, multi-model process consistently uncovers 3-5 bugs that the primary model overlooks.
To overcome the challenge of reviewing AI-generated code, have different LLMs like Claude and Codex review the code. Then, use a "peer review" prompt that forces the primary LLM to defend its choices or fix the issues raised by its "peers." This adversarial process catches more bugs and improves overall code quality.

An external AI reviewer provides more than just high-level feedback; it can identify specific, critical technical flaws. In one case, a reviewer AI caught a TOCTOU race condition vulnerability, suboptimal message ordering for LLM processing, and incorrect file type classifications—all of which were integrated and fixed by the primary AI.
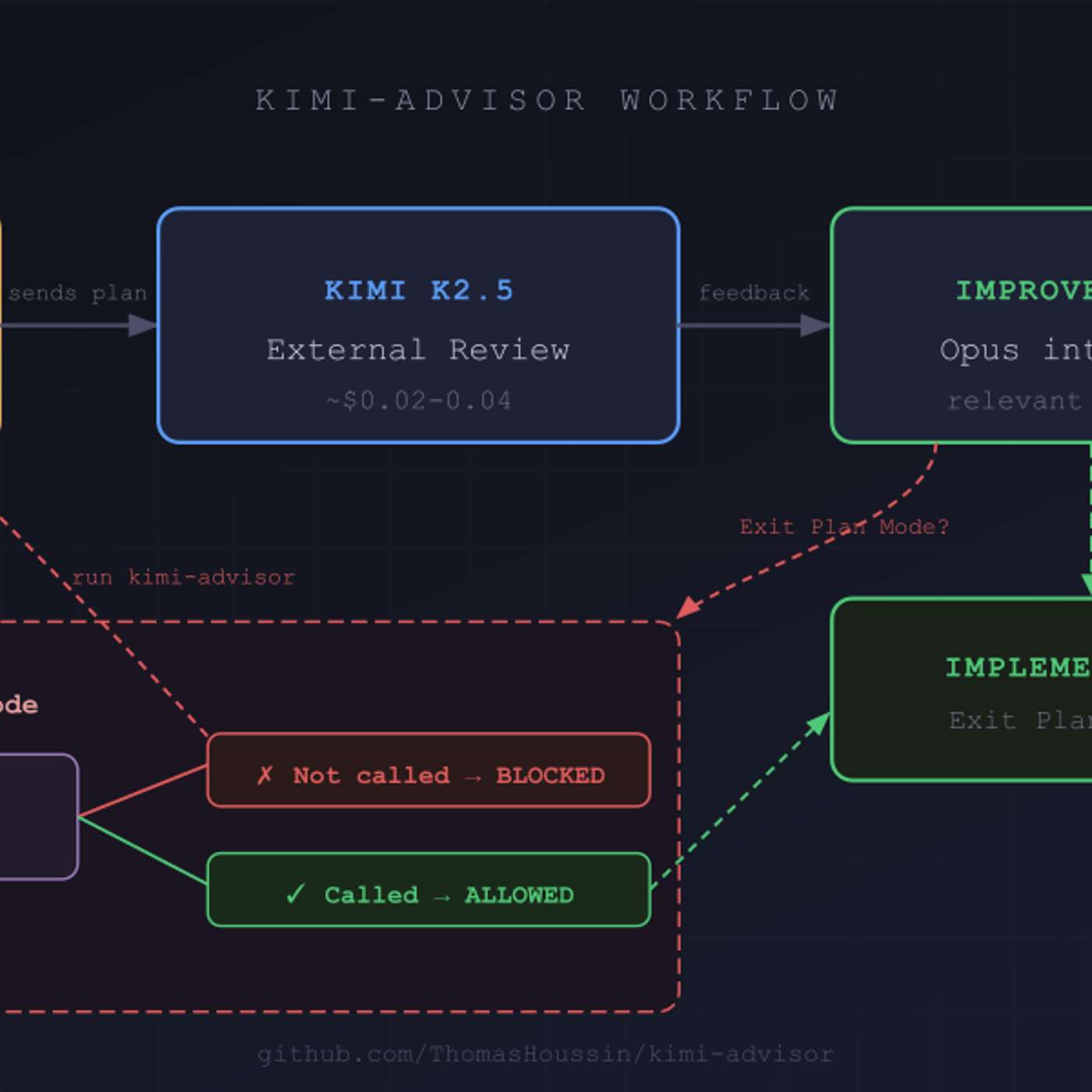
Prompting a different LLM model to review code generated by the first one provides a powerful, non-defensive critique. This "second opinion" can rapidly identify architectural issues, bugs, and alternative approaches without the human ego involved in traditional code reviews.

To avoid context drift in long AI sessions, create temporary, task-based agents with specialized roles. Use these agents as checkpoints to review outputs from previous steps and make key decisions, ensuring higher-quality results and preventing error propagation.

To improve the quality and accuracy of an AI agent's output, spawn multiple sub-agents with competing or adversarial roles. For example, a code review agent finds bugs, while several "auditor" agents check for false positives, resulting in a more reliable final analysis.

A powerful evaluation technique is to ask an AI agent to analyze its own poor output. The agent can review its context and process, explain why it made a mistake, and even suggest how to update its own instructions to prevent future errors.

Shopify's CTO argues against running many AI agents in parallel. A more effective, higher-quality method is a "critique loop," where one agent (ideally using a different model) reviews and suggests improvements to another's work. Though slower, this process significantly boosts code quality.
