Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
To get an objective critique of AI-generated content, use a dedicated 'reviewer' sub-agent. This separates the drafting and evaluation processes, preventing the original agent from being biased by its own creation and ensuring a higher quality output.

Related Insights
Generative AI is predictive and imperfect, unable to self-correct. A 'guardian agent'—a separate AI system—is required to monitor, score, and rewrite content produced by other AIs to enforce brand, style, and compliance standards, creating a necessary system of checks and balances.

Use Claude Cowork to spin up multiple "sub-agents" with distinct personas (e.g., your boss, customer, skeptic). These agents review your work from different perspectives, providing objective, multi-faceted feedback before you present it to real stakeholders.

By programming one AI agent with a skeptical persona to question strategy and check details, the overall quality and rigor of the entire multi-agent system increases, mirroring the effect of a critical thinker in a human team.

To improve the quality and accuracy of an AI agent's output, spawn multiple sub-agents with competing or adversarial roles. For example, a code review agent finds bugs, while several "auditor" agents check for false positives, resulting in a more reliable final analysis.

As AI agents generate vast amounts of output, human review becomes an impossible bottleneck. The solution emerging is multi-agent systems where a separate 'grading agent' automatically scores and requests revisions on an agent's work against a predefined rubric, as seen in Anthropic's 'Outcomes' feature, enabling scalable quality assurance.

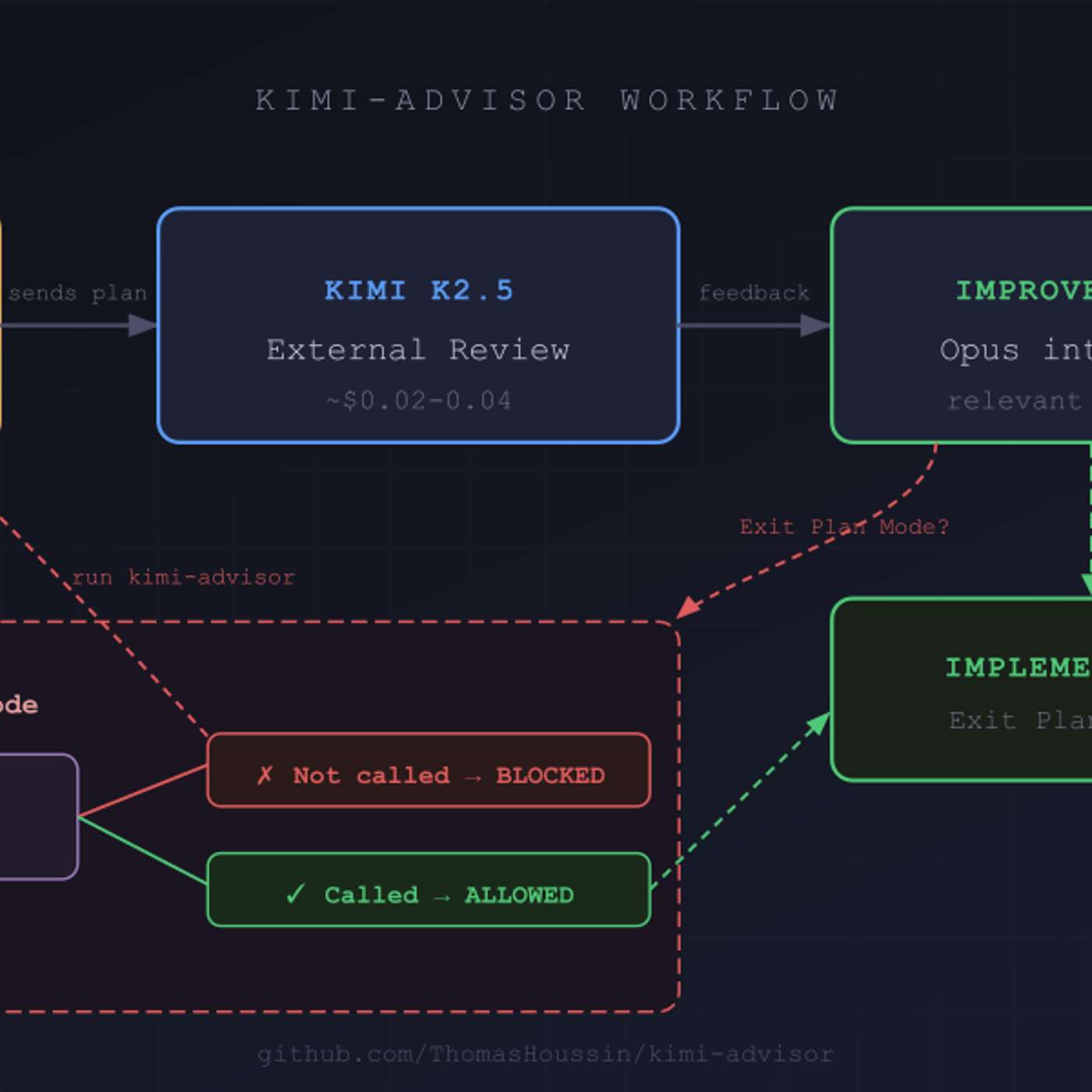
To improve code quality, use a secondary AI model from a different provider (e.g., Moonshot AI's Kimi) to review plans generated by a primary model (e.g., Anthropic's Claude). This introduces cognitive diversity and avoids the shared biases inherent in a single model family, leading to a more robust and enriching review process.
Generative AI models often have a built-in tendency to be overly complimentary and positive. Be aware of this bias when seeking feedback on ideas. Explicitly instruct the AI to be more critical, objective, or even brutal in its analysis to avoid being misled by unearned praise and get more valuable insights.

To prevent an LLM's performance from degrading in a long conversation, a phenomenon called "context rot," it is best to separate tasks. Use one context window for content generation and a new, fresh window for evaluation tasks like applying a rubric. This avoids bias and improves output quality.

Create a clear chain of command for AI agents. Allow a primary "builder" agent to spawn sub-agents for specific tasks, but hold it directly responsible for their output. The "reviewer" or quality agent, however, should be a singleton with no subordinates, acting as a final, singular gatekeeper like a principal engineer.

Using an LLM to grade another's output is more reliable when the evaluation process is fundamentally different from the task itself. For agentic tasks, the performer uses tools like code interpreters, while the grader analyzes static outputs against criteria, reducing self-preference bias.
