Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Instead of relying on a single AI model, Josh Pigford's workflow uses Opus for initial code generation and then runs a review pass with a different powerful model like GPT. This adversarial, multi-model process consistently uncovers 3-5 bugs that the primary model overlooks.

Related Insights
Relying on a single model family for generation and review is suboptimal. Blitzy found that using models from different developers (e.g., OpenAI, Anthropic) to check each other's work produces tremendously better results, as each family has distinct strengths and reasoning patterns.

To overcome the challenge of reviewing AI-generated code, have different LLMs like Claude and Codex review the code. Then, use a "peer review" prompt that forces the primary LLM to defend its choices or fix the issues raised by its "peers." This adversarial process catches more bugs and improves overall code quality.

An external AI reviewer provides more than just high-level feedback; it can identify specific, critical technical flaws. In one case, a reviewer AI caught a TOCTOU race condition vulnerability, suboptimal message ordering for LLM processing, and incorrect file type classifications—all of which were integrated and fixed by the primary AI.
Prompting a different LLM model to review code generated by the first one provides a powerful, non-defensive critique. This "second opinion" can rapidly identify architectural issues, bugs, and alternative approaches without the human ego involved in traditional code reviews.

To improve the quality and accuracy of an AI agent's output, spawn multiple sub-agents with competing or adversarial roles. For example, a code review agent finds bugs, while several "auditor" agents check for false positives, resulting in a more reliable final analysis.

Run two different AI coding agents (like Claude Code and OpenAI's Codex) simultaneously. When one agent gets stuck or generates a bug, paste the problem into the other. This "AI Ping Pong" leverages the different models' strengths and provides a "fresh perspective" for faster, more effective debugging.

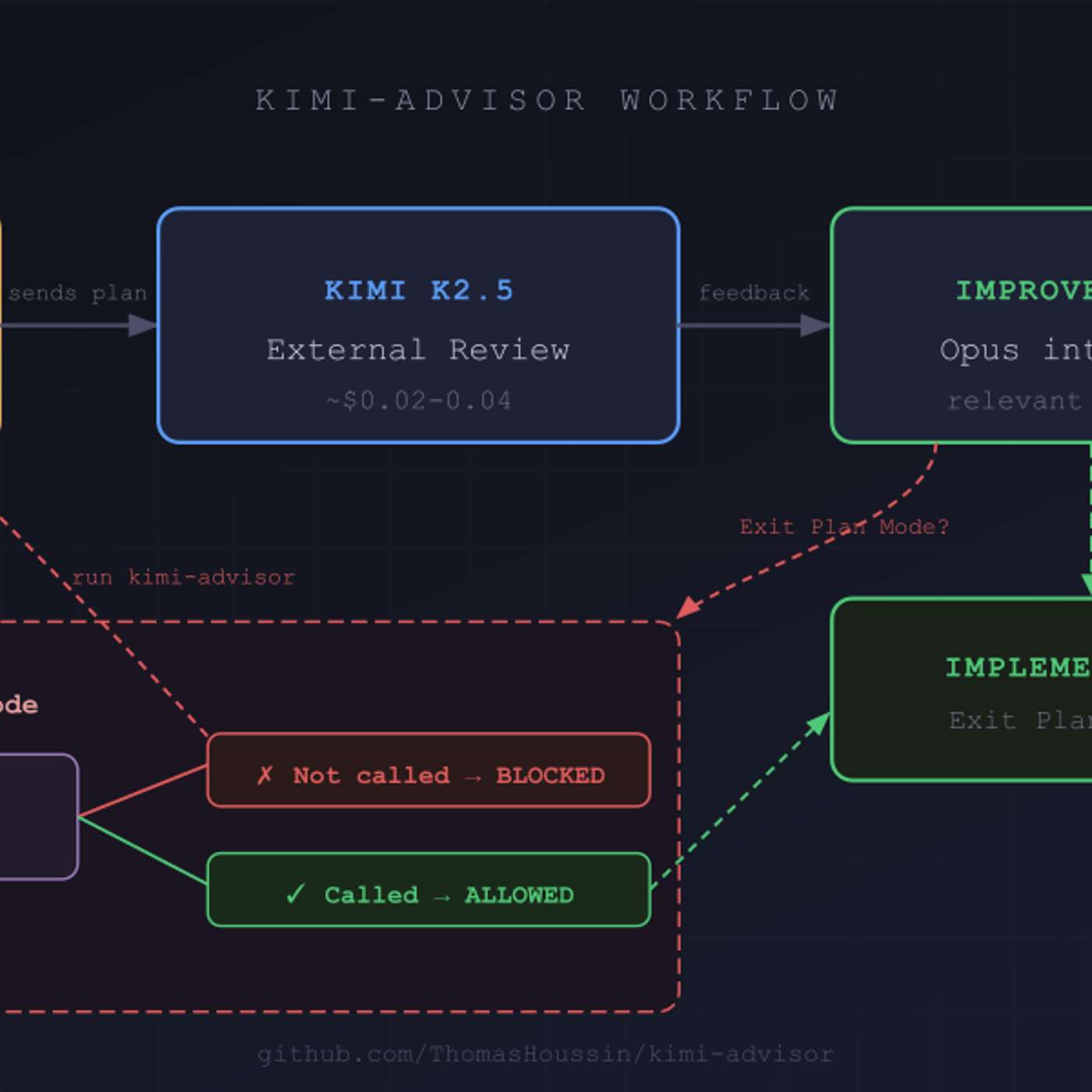
To improve code quality, use a secondary AI model from a different provider (e.g., Moonshot AI's Kimi) to review plans generated by a primary model (e.g., Anthropic's Claude). This introduces cognitive diversity and avoids the shared biases inherent in a single model family, leading to a more robust and enriching review process.
A powerful technique for creating robust software plans is to use AI as an adversarial partner. After drafting a specification, prompt an AI to "tear it apart" by identifying underspecified or inconsistent points. Iterate on this process until the AI's feedback becomes niche, indicating a solid spec.

Pigford developed a custom AI skill that acts as an adversarial check on the AI's own code. It's based on the premise that the AI "almost certainly screwed some stuff up," forcing it to re-evaluate and self-correct before human review, which consistently finds bugs.
Shopify's CTO argues against running many AI agents in parallel. A more effective, higher-quality method is a "critique loop," where one agent (ideally using a different model) reviews and suggests improvements to another's work. Though slower, this process significantly boosts code quality.
