Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
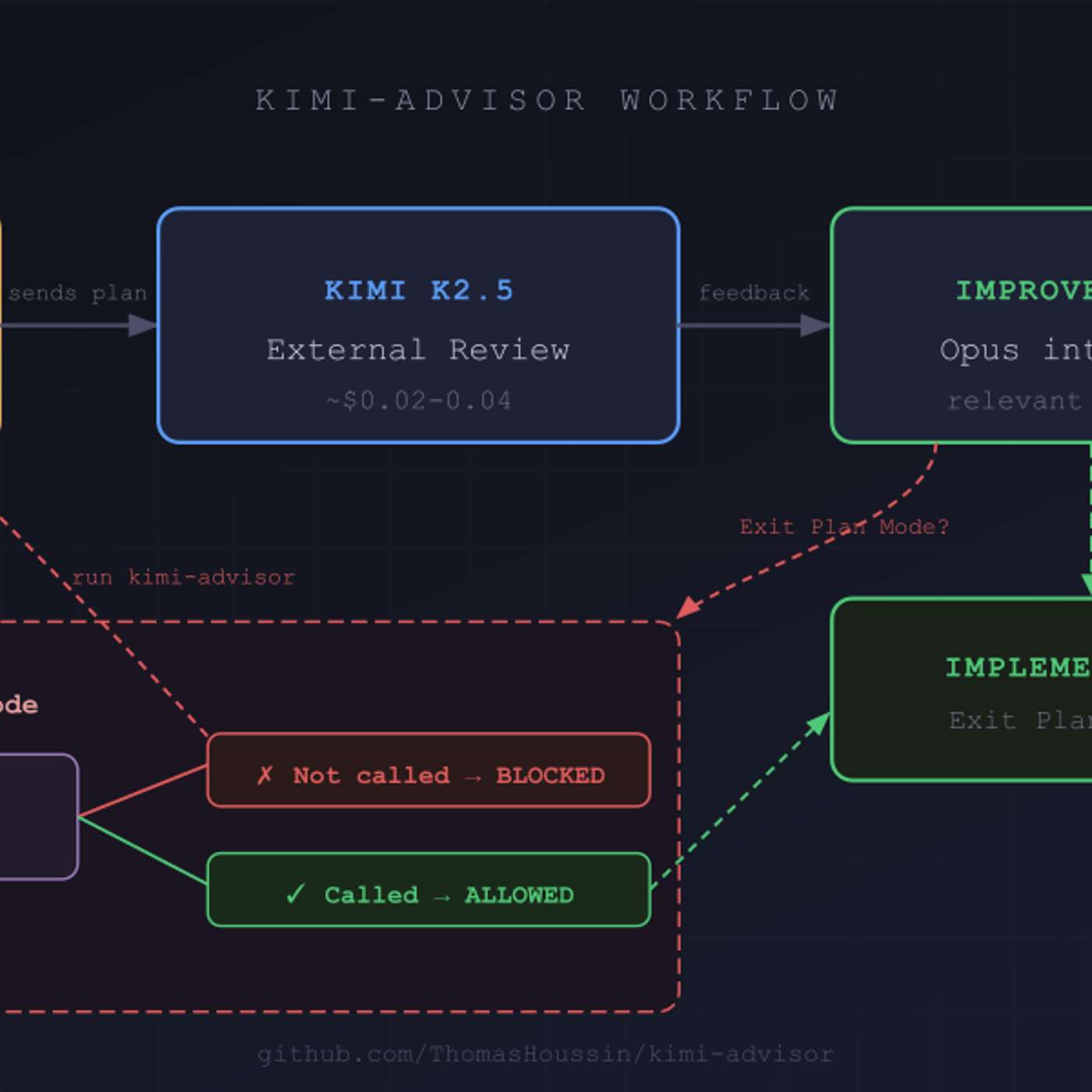
An external AI reviewer provides more than just high-level feedback; it can identify specific, critical technical flaws. In one case, a reviewer AI caught a TOCTOU race condition vulnerability, suboptimal message ordering for LLM processing, and incorrect file type classifications—all of which were integrated and fixed by the primary AI.
Related Insights
As AI coding agents generate vast amounts of code, the most tedious part of a developer's job shifts from writing code to reviewing it. This creates a new product opportunity: building tools that help developers validate and build confidence in AI-written code, making the review process less of a chore.

Relying on a single model family for generation and review is suboptimal. Blitzy found that using models from different developers (e.g., OpenAI, Anthropic) to check each other's work produces tremendously better results, as each family has distinct strengths and reasoning patterns.

Don't ask an LLM to perform initial error analysis; it lacks the product context to spot subtle failures. Instead, have a human expert write detailed, freeform notes ("open codes"). Then, leverage an LLM's strength in synthesis to automatically categorize those hundreds of human-written notes into actionable failure themes ("axial codes").

To overcome the challenge of reviewing AI-generated code, have different LLMs like Claude and Codex review the code. Then, use a "peer review" prompt that forces the primary LLM to defend its choices or fix the issues raised by its "peers." This adversarial process catches more bugs and improves overall code quality.

Prompting a different LLM model to review code generated by the first one provides a powerful, non-defensive critique. This "second opinion" can rapidly identify architectural issues, bugs, and alternative approaches without the human ego involved in traditional code reviews.

Solo developers can integrate AI tools like BugBot with GitHub to automatically review pull requests. These specialized AIs are trained to find security vulnerabilities and bugs that a solo builder might miss, providing a crucial safety net and peace of mind.

To improve the quality and accuracy of an AI agent's output, spawn multiple sub-agents with competing or adversarial roles. For example, a code review agent finds bugs, while several "auditor" agents check for false positives, resulting in a more reliable final analysis.

Instead of relying solely on human oversight, Bret Taylor advocates a layered "defense in depth" approach for AI safety. This involves using specialized "supervisor" AI models to monitor a primary agent's decisions in real-time, followed by more intensive AI analysis post-conversation to flag anomalies for efficient human review.

To improve code quality, use a secondary AI model from a different provider (e.g., Moonshot AI's Kimi) to review plans generated by a primary model (e.g., Anthropic's Claude). This introduces cognitive diversity and avoids the shared biases inherent in a single model family, leading to a more robust and enriching review process.
To prevent AI coding assistants from hallucinating, developer Terry Lynn uses a two-step process. First, an AI generates a Product Requirements Document (PRD). Then, a separate AI "reviewer" rates the PRD's clarity out of 10, identifying gaps before any code is written, ensuring a higher rate of successful execution.
