Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
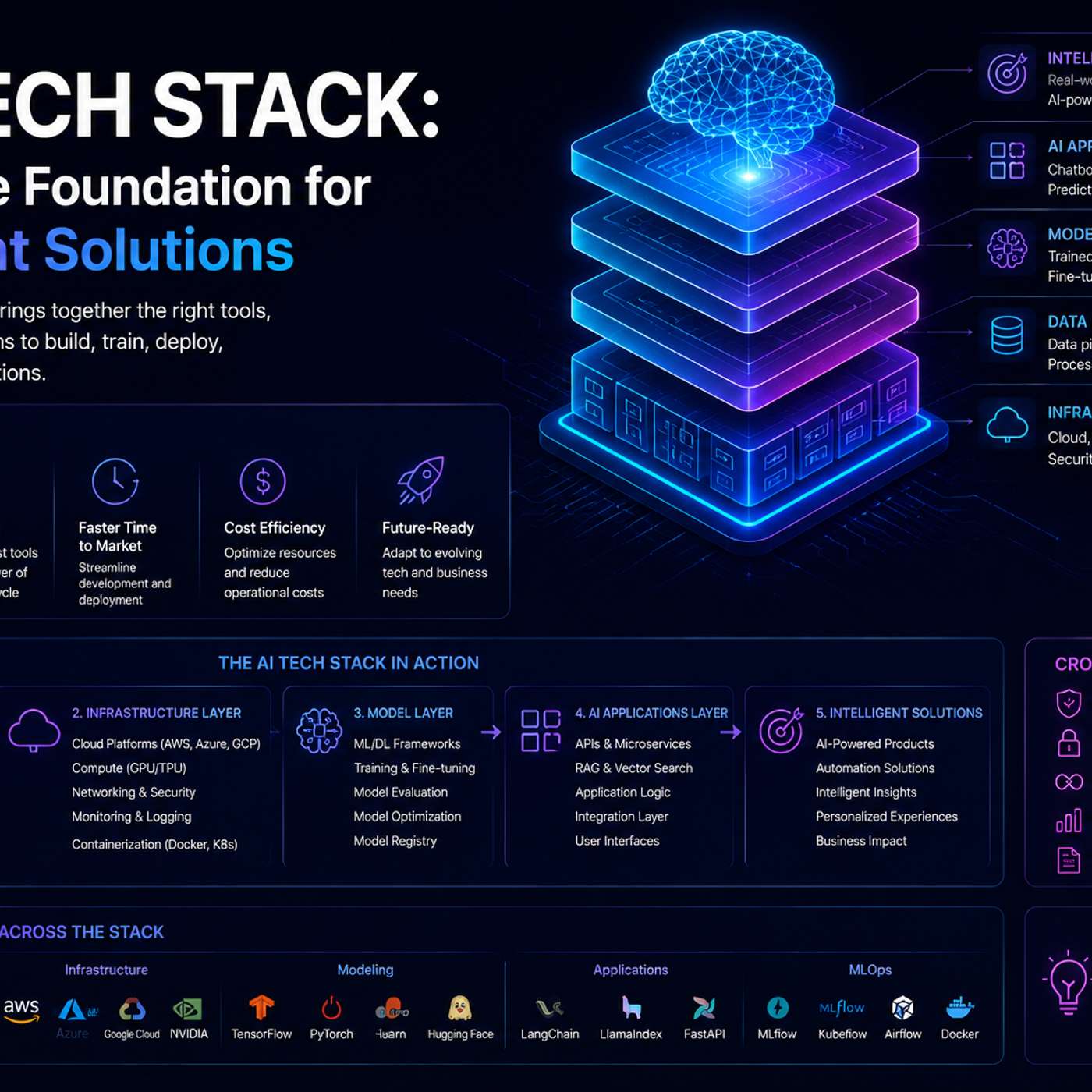
Integrating generative AI is not a simple model upgrade. It demands new architectural components like vector databases (e.g., Pinecone, Weaviate) for semantic search and prompt orchestration frameworks (e.g., LangChain) to manage complex model interactions and proprietary data.
Related Insights
Instead of interacting with a single LLM, users will increasingly call an API that represents a "system as a model." Behind the scenes, this triggers a complex orchestration of multiple specialized models, sub-agents, and tools to complete a task, while maintaining a simple user experience.

Effective agent memory is not merely a storage layer. It's an encapsulated system for learning and adaptation that integrates embedding models, re-rankers, databases, and LLMs, all working in concert to hold, move, and store data.

The early focus on crafting the perfect prompt is obsolete. Sophisticated AI interaction is now about 'context engineering': architecting the entire environment by providing models with the right tools, data, and retrieval mechanisms to guide their reasoning process effectively.

Enterprises will shift from relying on a single large language model to using orchestration platforms. These platforms will allow them to 'hot swap' various models—including smaller, specialized ones—for different tasks within a single system, optimizing for performance, cost, and use case without being locked into one provider.

While GenAI grabs headlines, its most practical enterprise use is as an intelligent orchestrator. It can call upon and synthesize results from highly effective traditional tools like time-series forecasting models or SQL databases, multiplying their value within a larger, more powerful system.

Vector search excels at semantic meaning but fails on precise keywords like product SKUs. Effective enterprise search requires a hybrid system combining the strengths of lexical search (e.g., BM25) for keywords and vector search for concepts to serve all user needs accurately.

A complete AI agent solution consists of five distinct layers: an Agent Harness (e.g., Cloud Code), a Search Layer (e.g., Perplexity), a Web Data Layer (e.g., FireCrawl), an Ops Brain (e.g., Obsidian), and an Outbound/Audience layer. Focusing only on the model is insufficient for building a robust product.

The focus in AI has shifted from crafting the perfect prompt (prompt engineering) to providing the right information (context engineering), and now to building the entire operational environment—tooling, systems, and access—that enables a model to perform complex tasks. This new paradigm is called harness engineering.

The nature of Retrieval-Augmented Generation (RAG) is evolving. Instead of a single search to populate an initial context window, AI agents are now performing numerous concurrent queries in a single turn. This allows them to explore diverse information paths simultaneously, driving new database requirements.
To fully leverage rapidly improving AI models, companies cannot just plug in new APIs. Notion's co-founder reveals they completely rebuild their AI system architecture every six months, designing it around the specific capabilities of the latest models to avoid being stuck with suboptimal implementations.
