Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Avoid large, resource-intensive NLP models like spaCy by implementing a multi-layered intent parser. This approach uses exact matches, prefix matches, and typo tolerance (Levenstein distance) to achieve fast, efficient, and offline intent recognition with zero dependencies, even across multiple languages.

Related Insights
Adopt a "start simple" approach for AI development. Master prompting first. If that fails, use Retrieval Augmented Generation (RAG). Fine-tuning should be the last resort due to its complexity in deployment, serving, and keeping up with rapidly evolving base models.

As models become more powerful, the primary challenge shifts from improving capabilities to creating better ways for humans to specify what they want. Natural language is too ambiguous and code too rigid, creating a need for a new abstraction layer for intent.

The path to robust AI applications isn't a single, all-powerful model. It's a system of specialized "sub-agents," each handling a narrow task like context retrieval or debugging. This architecture allows for using smaller, faster, fine-tuned models for each task, improving overall system performance and efficiency.
Small language models (SLMs) are cost-effective but can easily lose track of complex tasks. 'Harness engineering' is an emerging discipline that involves building a software wrapper around an SLM. This 'harness' forces the model to check in and stay focused, enabling cheaper models to reliably perform sophisticated tasks.

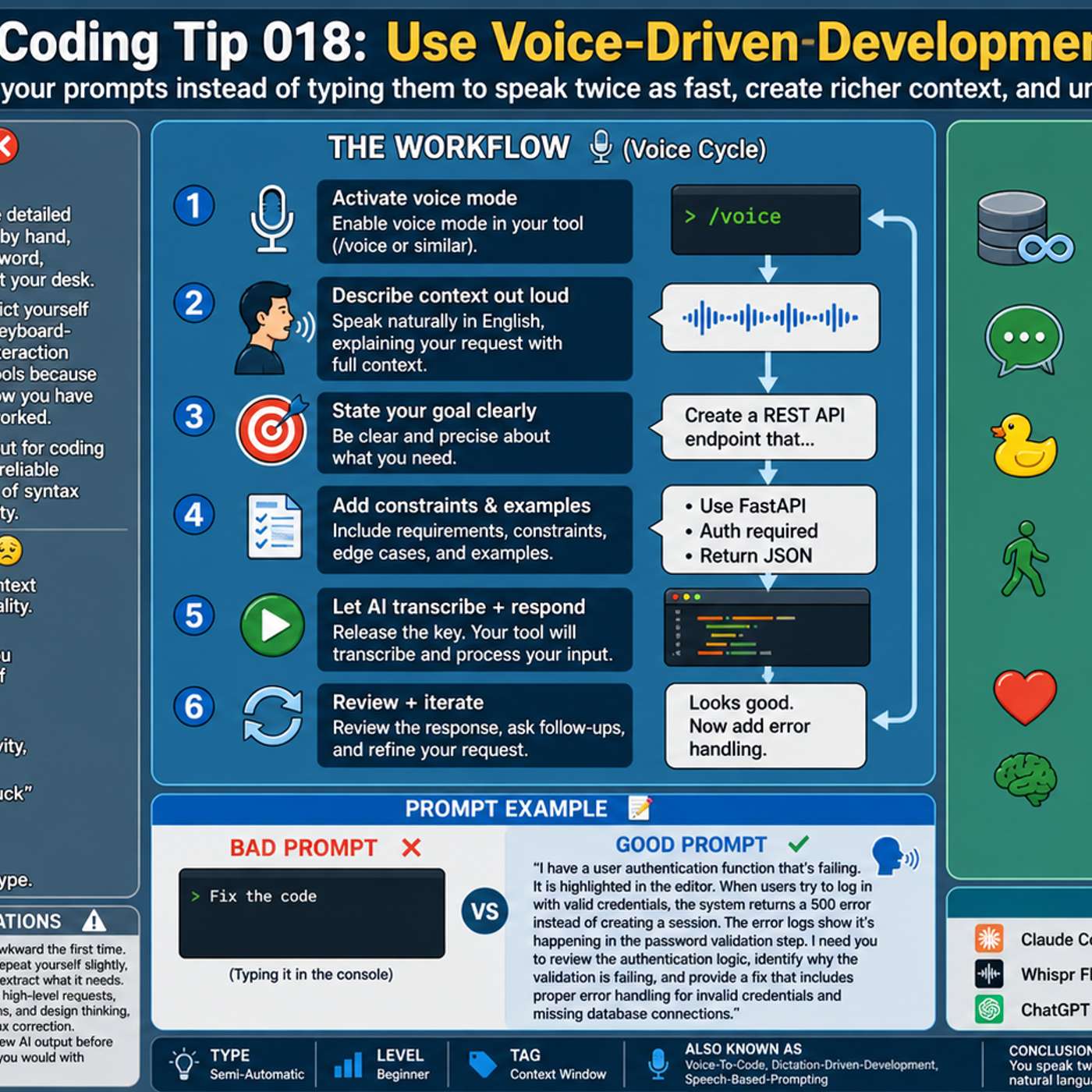
Unlike past speech recognition that failed by requiring precise syntax, modern AI assistants can interpret natural, conversational language. They infer the user's intent, successfully translating it into code without needing perfectly dictated syntax like angle brackets or semicolons.
The AI agent startup Hey Clicky employs a sophisticated harness. It uses the fast and cheap GPT real-time model to interpret user intent and then route the request to a more capable but expensive model like Fable 5, optimizing both cost and performance.

Breaking from transformer dominance, Shopify leverages Liquid AI's state-space-like models for high-value tasks. For search query understanding, they run a 300M parameter Liquid model with an impressive 30ms end-to-end latency, a feat difficult to achieve with traditional architectures.

Purely probabilistic LLMs are unreliable for critical business processes. GetVocal's architecture uses a deterministic "context graph" based on user intentions as the core decision-making engine. This provides traceability and reliability, while selectively calling generative models for conversational nuance.

A cost-effective AI architecture involves using a small, local model on the user's device to pre-process requests. This local AI can condense large inputs into an efficient, smaller prompt before sending it to the expensive, powerful cloud model, optimizing resource usage.

Large API models can often interpret vague or 'lazy' prompts, but smaller local models like Gemma require precise, well-structured instructions to generate useful output. This shift demands a more disciplined approach to prompt engineering for developers using local AI.
