Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
For unpredictable situations where a robot has no prior training data (e.g., a "gas leak" sign), multimodal LLMs can provide the necessary world knowledge to reason and act appropriately. This solves the long-standing robotics problem of how to handle the long tail of real-world scenarios.
![Sergey Levine - Building LLMs for the Physical World - [Invest Like the Best, EP.465] thumbnail](https://megaphone.imgix.net/podcasts/fdcd4328-2c77-11f1-a72b-977309fd08f1/image/b1bb4368d6e13a4a804924681ffe3ab1.jpg?ixlib=rails-4.3.1&max-w=3000&max-h=3000&fit=crop&auto=format,compress)
Related Insights
Unlike LLMs that train on the existing internet, robotics lacks a pre-training dataset for the physical world. This forces companies like Encore to build a full-stack solution combining a software platform for data management with human-led operations for data collection, annotation, and even real-time remote robot piloting for exception handling.

While language models understand the world through text, Demis Hassabis argues they lack an intuitive grasp of physics and spatial dynamics. He sees 'world models'—simulations that understand cause and effect in the physical world—as the critical technology needed to advance AI from digital tasks to effective robotics.

The Physical Intelligence thesis is that a foundation model learning from diverse data can achieve a "physical understanding" of the world, making it easier to adapt to new tasks than building single-purpose robots from scratch. Generality leverages broader data, which is ultimately a more scalable approach.
Large Language Models struggle with obvious, real-world facts because their training data (text) over-represents uncertain topics open to debate—the 'maybe sphere.' Bedrock, common-sense knowledge is rarely written down, leaving a significant gap in the AI's world model and creating a need for human oversight on obvious matters.

Large language models are insufficient for tasks requiring real-world interaction and spatial understanding, like robotics or disaster response. World models provide this missing piece by generating interactive, reason-able 3D environments. They represent a foundational shift from language-based AI to a more holistic, spatially intelligent AI.

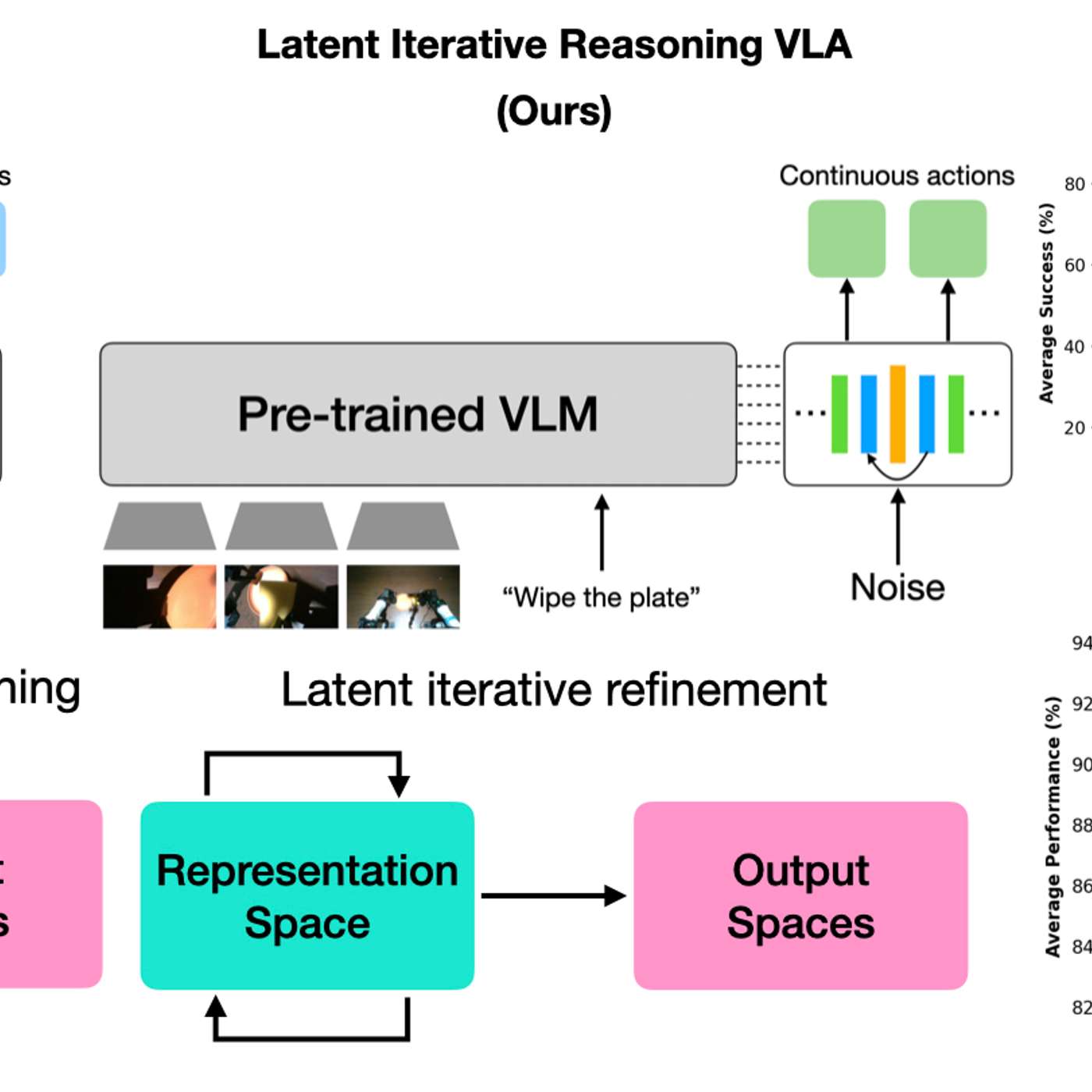
A new model architecture allows robots to vary their internal 'thinking' iterations at test time. This lets practitioners trade response speed for decision accuracy on a case-by-case basis, boosting performance on complex tasks without needing to retrain the model.
The AI's ability to handle novel situations isn't just an emergent property of scale. Waive actively trains "world models," which are internal generative simulators. This enables the AI to reason about what might happen next, leading to sophisticated behaviors like nudging into intersections or slowing in fog.

Robots have become so capable at low-level physical tasks that the primary bottleneck has shifted to "mid-level reasoning"—interpreting a scene and choosing the correct next action. This means improvement can come from high-level language-based coaching, not just more physical demonstration data, which is a major breakthrough.
LLMs are trained to produce high-probability, common information, making it hard to surface rare knowledge. The solution is to programmatically create prompts that combine unlikely concepts. This forces the model into an improbable state, compelling it to search the long tail of its knowledge base rather than relying on common associations.

Unlike older robots requiring precise maps and trajectory calculations, new robots use internet-scale common sense and learn motion by mimicking humans or simulations. This combination has “wiped the slate clean” for what is possible in the field.
