Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Robots have become so capable at low-level physical tasks that the primary bottleneck has shifted to "mid-level reasoning"—interpreting a scene and choosing the correct next action. This means improvement can come from high-level language-based coaching, not just more physical demonstration data, which is a major breakthrough.
![Sergey Levine - Building LLMs for the Physical World - [Invest Like the Best, EP.465] thumbnail](https://megaphone.imgix.net/podcasts/fdcd4328-2c77-11f1-a72b-977309fd08f1/image/b1bb4368d6e13a4a804924681ffe3ab1.jpg?ixlib=rails-4.3.1&max-w=3000&max-h=3000&fit=crop&auto=format,compress)
Related Insights
To build generalist robots, the most effective approach is pre-training foundation models on internet-scale video datasets, not just simulation or tele-operated data. This vast, diverse data provides a deep, implicit understanding of physics and object interaction that is impossible to replicate in controlled environments, enabling true generalization.

While LLMs dominate headlines, Dr. Fei-Fei Li argues that "spatial intelligence"—the ability to understand and interact with the 3D world—is the critical, underappreciated next step for AI. This capability is the linchpin for unlocking meaningful advances in robotics, design, and manufacturing.

Physical Intelligence demonstrated an emergent capability where its robotics model, after reaching a certain performance threshold, significantly improved by training on egocentric human video. This solves a major bottleneck by leveraging vast, existing video datasets instead of expensive, limited teleoperated data.

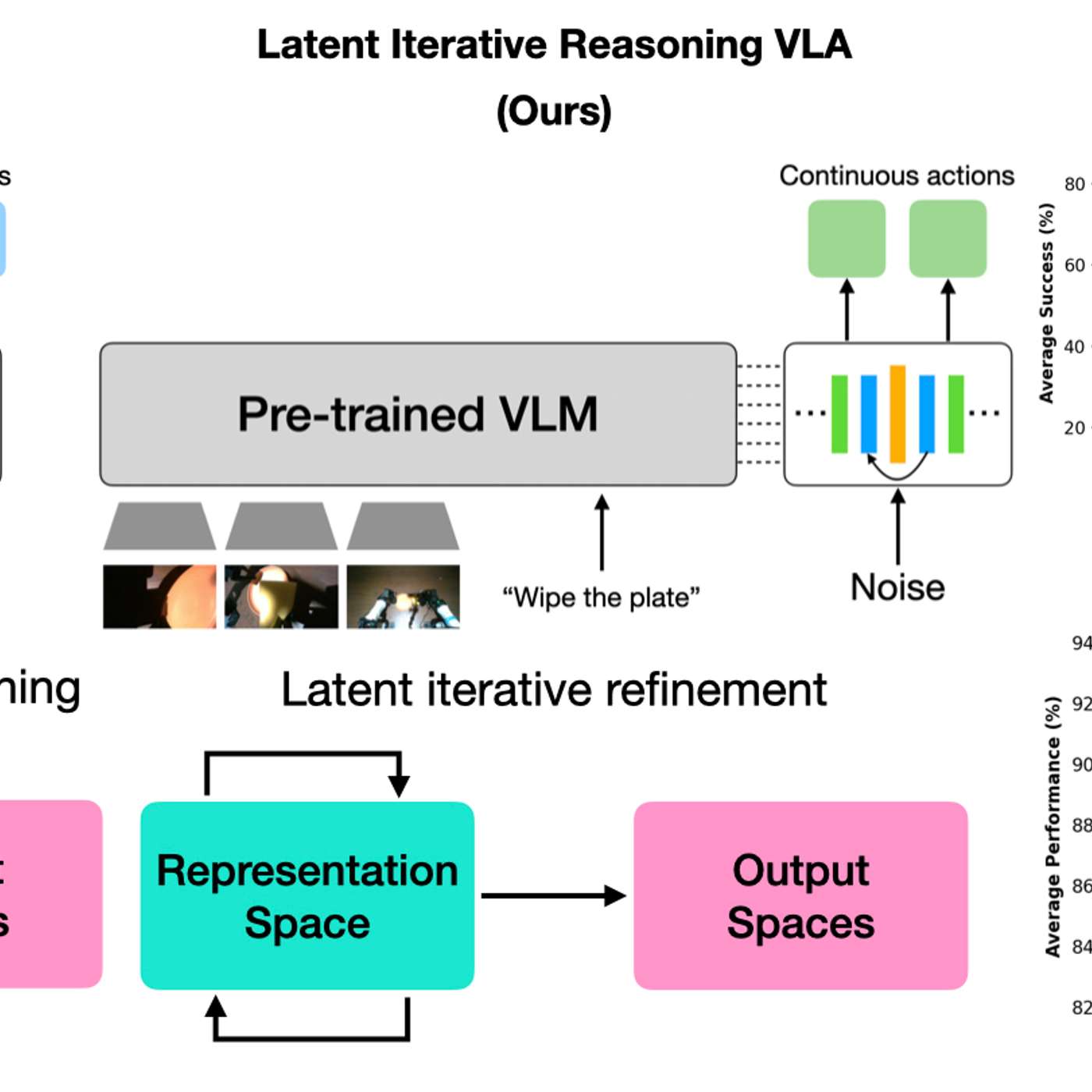
A new model architecture allows robots to vary their internal 'thinking' iterations at test time. This lets practitioners trade response speed for decision accuracy on a case-by-case basis, boosting performance on complex tasks without needing to retrain the model.
The adoption of powerful AI architectures like transformers in robotics was bottlenecked by data quality, not algorithmic invention. Only after data collection methods improved to capture more dexterous, high-fidelity human actions did these advanced models become effective, reversing the typical 'algorithm-first' narrative of AI progress.

Ken Goldberg quantifies the challenge: the text data used to train LLMs would take a human 100,000 years to read. Equivalent data for robot manipulation (vision-to-control signals) doesn't exist online and must be generated from scratch, explaining the slower progress in physical AI.

For unpredictable situations where a robot has no prior training data (e.g., a "gas leak" sign), multimodal LLMs can provide the necessary world knowledge to reason and act appropriately. This solves the long-standing robotics problem of how to handle the long tail of real-world scenarios.
While "AI" is a common buzzword, the most significant recent advancement enabling flexible automation is the maturity of vision systems. These systems allow robots to identify and locate objects in a general space, removing the old constraint of needing perfectly pre-programmed, fixed coordinates for every action.

Human intelligence is multifaceted. While LLMs excel at linguistic intelligence, they lack spatial intelligence—the ability to understand, reason, and interact within a 3D world. This capability, crucial for tasks from robotics to scientific discovery, is the focus for the next wave of AI models.

Unlike older robots requiring precise maps and trajectory calculations, new robots use internet-scale common sense and learn motion by mimicking humans or simulations. This combination has “wiped the slate clean” for what is possible in the field.
