Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Diffusion models naturally reconstruct images in layers. In early denoising stages with high noise, they focus on low-frequency information like overall composition and color. As noise decreases in later steps, they add high-frequency details like textures and sharp edges. This hierarchical process is key to understanding their behavior.

Related Insights
The SNR-T bias can be fixed efficiently without retraining models. At each denoising step, the image is broken into frequency bands using wavelets. Each band is then given a small correction based on its specific noise mismatch before being recombined. This surgical approach is computationally cheap and universally effective.
Avoid writing long, paragraph-style prompts from the start as they are difficult to troubleshoot. Instead, begin with a condensed, 'boiled down' prompt containing only core elements. This establishes a working baseline, making it easier to iterate and add details incrementally.

Unlike simple classification (one pass), generative AI performs recursive inference. Each new token (word, pixel) requires a full pass through the model, turning a single prompt into a series of demanding computations. This makes inference a major, ongoing driver of GPU demand, rivaling training.

Instead of random prompting, break down any desired photo into its fundamental components like shot type, lighting, camera, and lens. Controlling these variables gives you precise, repeatable results and makes iteration faster, as you know exactly which element to adjust.
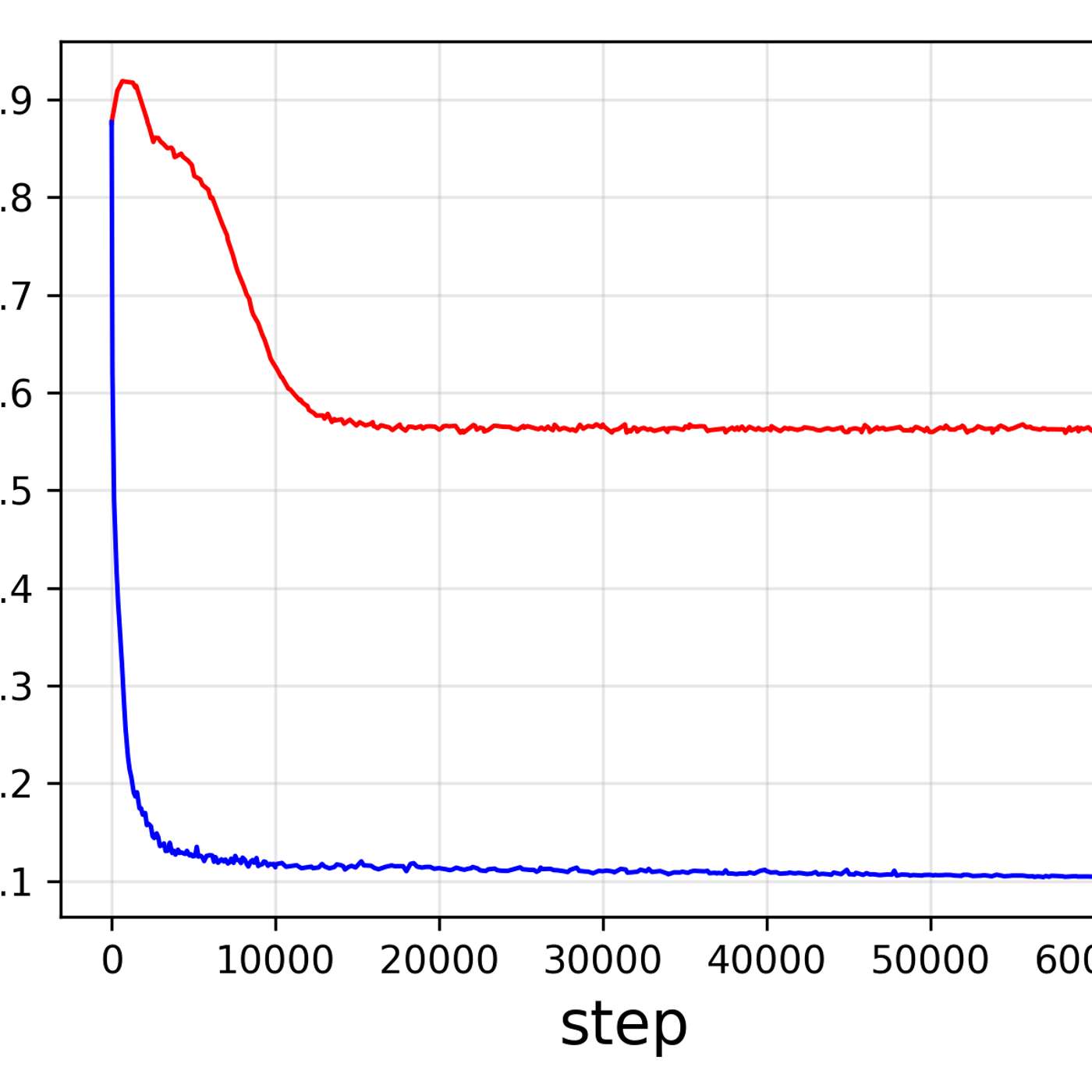
During training, diffusion models learn a perfect relationship between noise level (SNR) and denoising step (T). During inference, this relationship breaks as the model's own predictions introduce errors, creating SNR values it never trained on for a given step. This causes compounding errors and quality loss.
Models like Stable Diffusion achieve massive compression ratios (e.g., 50,000-to-1) because they aren't just storing data; they are learning the underlying principles and concepts. The resulting model is a compact 'filter' of intelligence that can generate novel outputs based on these learned principles.

Don't accept the false choice between AI generation and professional editing tools. The best workflows integrate both, allowing for high-level generation and fine-grained manual adjustments without giving up critical creative control.
The process of an AI like Stable Diffusion creating a coherent image by finding patterns within a vast possibility space of random noise serves as a powerful analogy. It illustrates how consciousness might render a structured reality by selecting and solidifying possibilities from an infinite field of potential experiences.
The ability of a single encoder to excel at both understanding and generating images indicates these two tasks are not as distinct as they seem. It suggests they rely on a shared, fundamental structure of visual information that can be captured in one unified representation.
When analyzing video, new generative models can create entirely new images that illustrate a described scene, rather than just pulling a direct screenshot. This allows AI to generate its own 'B-roll' or conceptual art that captures the essence of the source material.