Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Ambitious AI projects may fail their primary goal but still produce valuable secondary assets. An attempt to predict memory prices with an LLM failed, but the automated data gathering process created a first-of-its-kind historical analysis dashboard, which proved to be a more valuable outcome.

Related Insights
When developing internal AI tools, adopt a 'fail fast' mantra. Many use cases fail not because the idea is bad, but because the underlying models aren't yet capable. It's critical to regularly revisit these failed projects, as rapid advancements in AI can quickly make a previously unfeasible idea viable.

Turing operates in two markets: providing AI services to enterprises and training data to frontier labs. Serving enterprises reveals where models break in practice (e.g., reading multi-page PDFs). This knowledge allows Turing to create targeted, valuable datasets to sell back to the model creators, creating a powerful feedback loop.

The researchers' failure case analysis is highlighted as a key contribution. Understanding why the model fails—due to ambiguous data or unusual inputs—provides a realistic scope of application and a clear roadmap for improvement, which is more useful for practitioners than high scores alone.
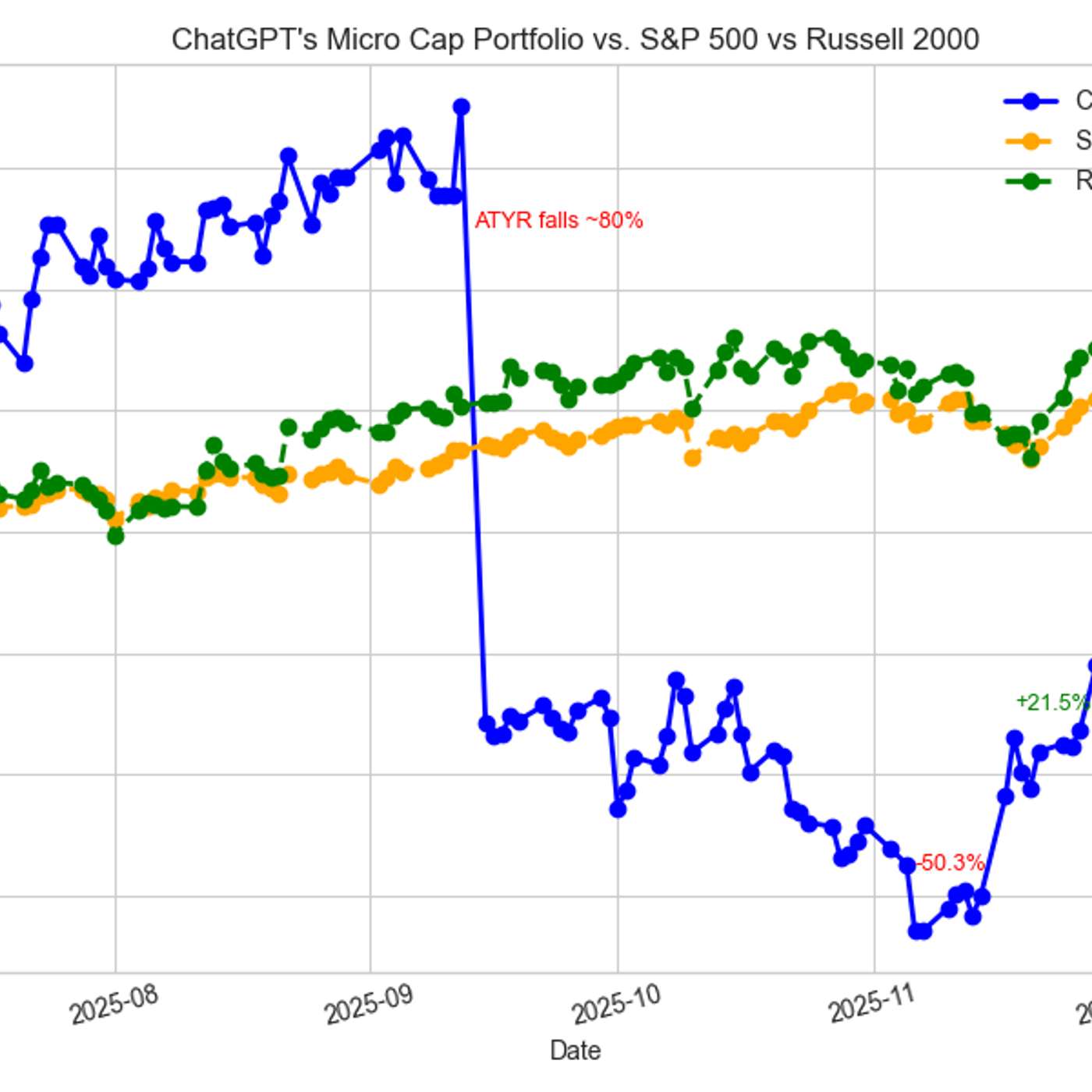
The project's true value is evolving beyond simple profit and loss. The creator is now developing a dedicated benchmarking tool, noting its new direction is "far more important and less explored in the LLM trading ecosystem." This suggests the primary output is not alpha, but rather foundational tooling and infrastructure for the emerging field of AI-driven finance.
With public data exhausted, AI companies are seeking proprietary datasets. After being rejected by established firms wary of sharing their 'crown jewels,' these labs are now acquiring the codebases of failed startups for tens of thousands of dollars as a novel source of high-quality training data.

In a new technological wave like AI, a high project failure rate is desirable. It indicates that a company is aggressively experimenting and pushing boundaries to discover what provides real value, rather than being too conservative.

The 85% AI project failure rate isn't a technology problem. It stems from four business and process issues: failing to identify a narrow use case, using data that isn't clean or ready, not defining success and risk, and applying deterministic Agile methods to probabilistic AI development.

Beyond automating data collection, investment firms can use AI to generate novel analytical frameworks. By asking AI to find new ways to plot and interpret data inputs, the team moves from rote data entry to higher-level analysis, using the technology as a creative and strategic partner.
A powerful but unintuitive AI development pattern is to give a model a vague goal and let it attempt a full implementation. This "throwaway" draft, with its mistakes and unexpected choices, provides crucial insights for writing a much more accurate plan for the final version.

YipitData had data on millions of companies but could only afford to process it for a few hundred public tickers due to high manual cleaning costs. AI and LLMs have now made it economically viable to tag and structure this messy, long-tail data at scale, creating massive new product opportunities.
