The researchers' failure case analysis is highlighted as a key contribution. Understanding why the model fails—due to ambiguous data or unusual inputs—provides a realistic scope of application and a clear roadmap for improvement, which is more useful for practitioners than high scores alone.
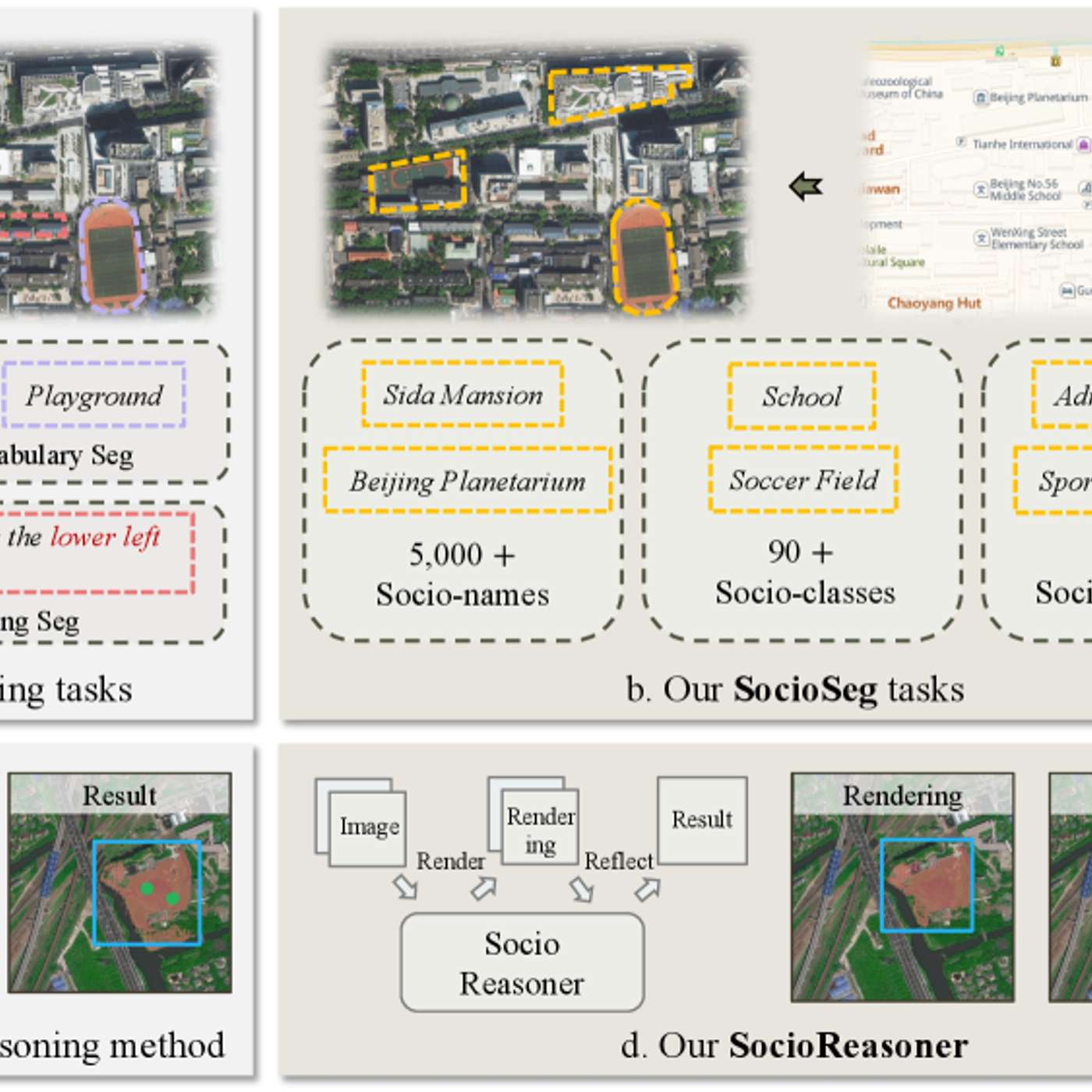
The featured AI model succeeds by reframing urban analysis as a reasoning problem. It uses a two-stage process—generating broad hypotheses then refining with detailed evidence—which mimics human cognition and outperforms traditional single-pass pattern recognition systems.
The AI system is fine-tuned using reinforcement learning (RL) instead of standard backpropagation. This allows it to learn from a simple reward signal (correct segmentation), cleverly bypassing the problem that key parts of its process are not mathematically differentiable.