Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
The holy grail of databases is unifying transactional (OLTP) and analytical (OLAP) workloads. Instead of a single compromised "HTAP" engine, Databricks' "LTAP" writes OLTP data in a queryable columnar format. This allows separate, optimized engines to access the same live data, killing brittle CDC pipelines.

Related Insights
Stonebraker asserts that specialized database architectures (e.g., column stores, stream processors) are an order of magnitude faster for their specific use cases than general-purpose row stores like Postgres. While Postgres is a great "lowest common denominator," at the high end, a tailored solution is necessary for optimal performance.

Denodo's logical approach is significantly faster because it fetches only the specific query results needed for an analysis, rather than physically moving entire datasets into a central repository. This is analogous to getting a single cup of water from a pitcher instead of carrying the entire heavy pitcher, explaining a 75% reduction in integration time.

AI agents make it dramatically easier to extract and migrate data from platforms, reducing vendor lock-in. In response, platforms like Snowflake are embracing open file formats (e.g., Iceberg), shifting the competitive basis from data gravity to superior performance, cost, and features.

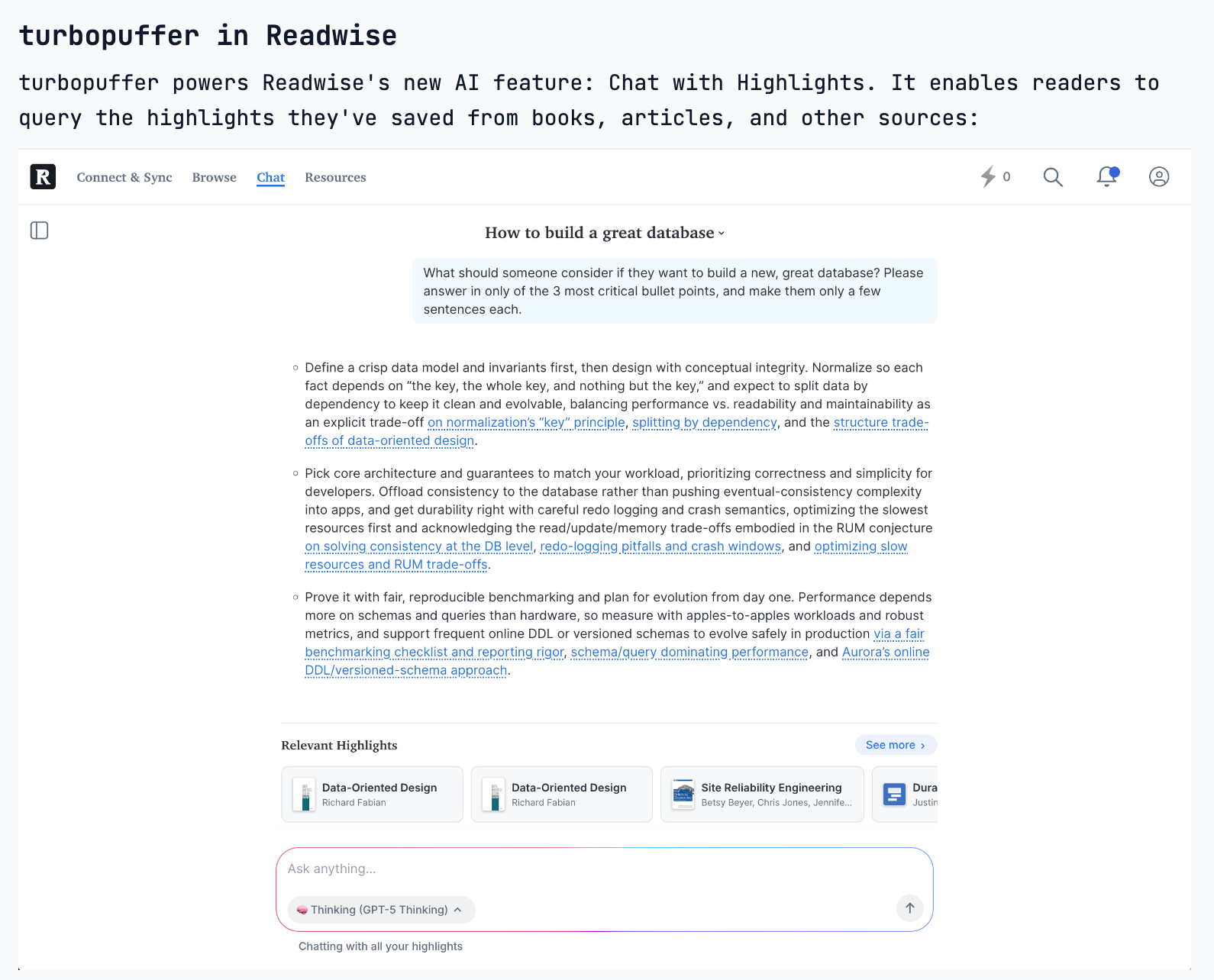
To build a multi-billion dollar database company, you need two things: a new, widespread workload (like AI needing data) and a fundamentally new storage architecture that incumbents can't easily adopt. This framework helps identify truly disruptive infrastructure opportunities.

Databricks and Snowflake took opposite approaches. Snowflake optimized for fast queries on curated, proprietary "downstream" data. Databricks focused on large-scale, messy "upstream" data ingestion using open formats. Databricks found it easier to add speed than it was for Snowflake to move upstream and abandon its proprietary lock-in.
Truly massive database companies only emerge every ~15 years when three conditions are met: a new ubiquitous workload (like AI), a new underlying storage architecture that predecessors can't adopt (like NVMe SSDs and S3), and a long-term roadmap to handle all possible data queries.
Ali Ghodsi argues that while public LLMs are a commodity, the true value for enterprises is applying AI to their private data. This is impossible without first building a modern data foundation that allows the AI to securely and effectively access and reason on that information.

The traditional approach of building a central data lake fails because data is often stale by the time migration is complete. The modern solution is a 'zero copy' framework that connects to data where it lives. This eliminates data drift and provides real-time intelligence without endless, costly migrations.

To rewrite its core database engine, Databricks first built a simulation "factory." This system uses machine learning on a decade of query traces (quadrillions of data points) to model and predict the performance of new algorithms and data structures, de-risking the project and avoiding "second system syndrome."
The viability of Databricks' core LTAP architecture was heavily debated. While leadership discussed it from first principles, a single engineer built a prototype. He proved that transcoding data from row to columnar format could be done using idle storage-fleet CPUs, ending the debate and unlocking the strategy.