Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Stonebraker asserts that specialized database architectures (e.g., column stores, stream processors) are an order of magnitude faster for their specific use cases than general-purpose row stores like Postgres. While Postgres is a great "lowest common denominator," at the high end, a tailored solution is necessary for optimal performance.

Related Insights
Stonebraker clarifies that GPUs excel at parallel processing (SIMD), but database indexing (e.g., traversing a B-tree) is a serial process. Each step involves following a pointer to a new memory location, a sequence of operations that cannot be parallelized effectively, making GPUs unsuitable for accelerating this core database function.
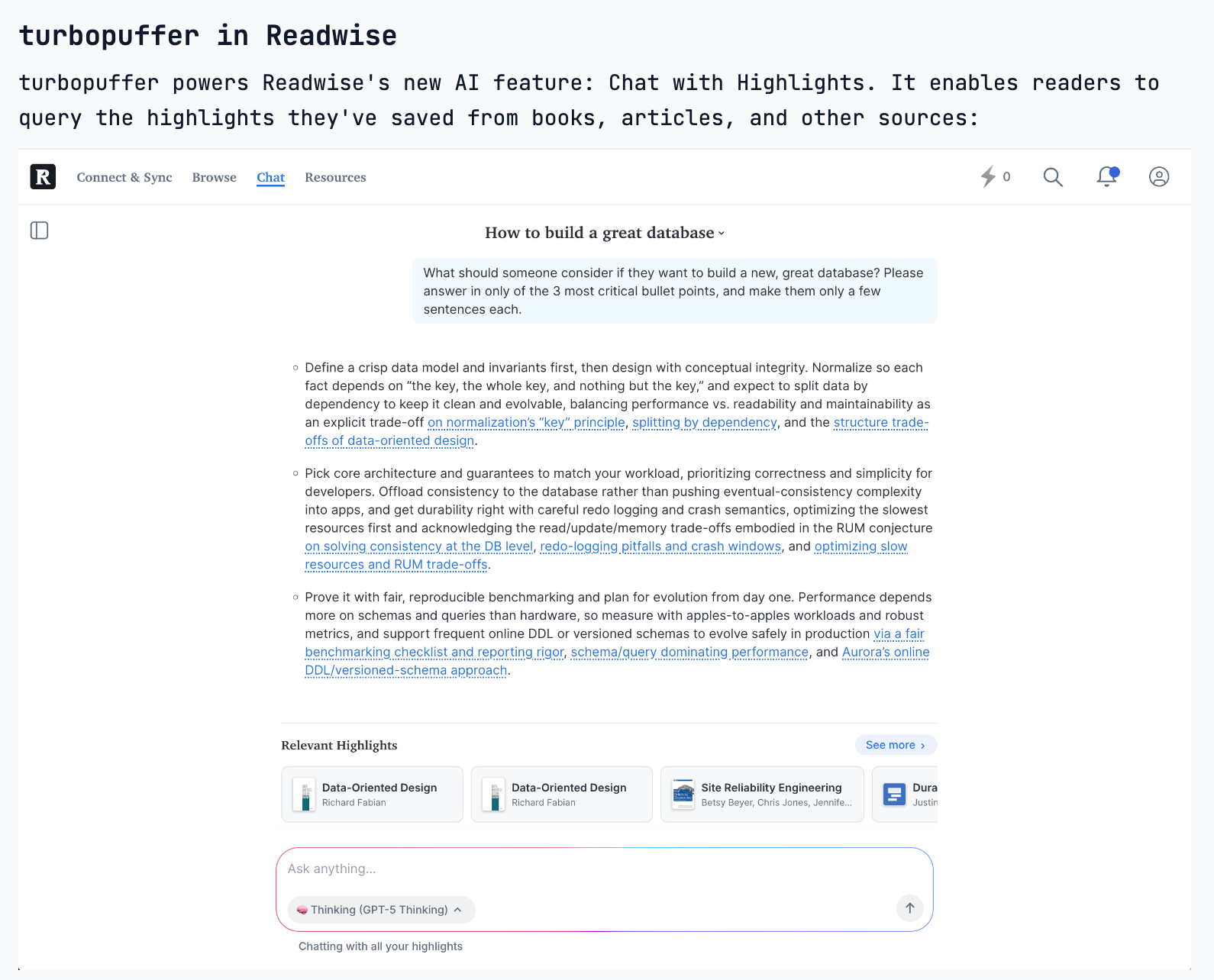
The most difficult engineering tasks aren't flashy UI features, but backend architectural changes. Refactoring a database schema to be more flexible is invisible to users but is crucial for long-term development speed and product scalability. Prioritizing this "boring" work is a key strategic decision.

Ingress, Stonebraker's first database, couldn't handle non-standard data types like polygons for GIS or custom calendars for financial bonds. Postgres was engineered with an extendable type system to solve this fundamental limitation, making it vastly more flexible for diverse applications beyond standard business data processing.
To build a multi-billion dollar database company, you need two things: a new, widespread workload (like AI needing data) and a fundamentally new storage architecture that incumbents can't easily adopt. This framework helps identify truly disruptive infrastructure opportunities.

Just as developers use various databases for different needs, AI applications will rely on a "constellation" of specialized models. Some tasks will require expensive, high-reasoning models, while others will prioritize low-latency or low-cost models. The market will become heterogeneous, not monolithic.

In systems like Kubernetes, most components like API servers and schedulers can be scaled out by adding more instances. The true bottleneck preventing an order-of-magnitude scale increase is the consistent storage layer (e.g., etcd). All major scaling efforts eventually focus on optimizing or replacing this single, critical component.
Stonebraker's research reveals that on real production data warehouse benchmarks, LLMs achieve 0% accuracy. This is due to messy, non-mnemonic schemas, complex 100+ line queries, and domain-specific data not found in training sets—factors absent from simplified academic benchmarks like Spider and Bird.
Stonebraker claims the tech world blindly followed Google's lead on MapReduce, which was "ridiculously inefficient" compared to distributed databases. He also slams eventual consistency for failing to guarantee data integrity (e.g., preventing stock from going below zero), a tradeoff most enterprises cannot make. Google later abandoned both concepts.
Truly massive database companies only emerge every ~15 years when three conditions are met: a new ubiquitous workload (like AI), a new underlying storage architecture that predecessors can't adopt (like NVMe SSDs and S3), and a long-term roadmap to handle all possible data queries.
The DBOS project, co-founded by Stonebraker, argues operating systems primarily manage data at scale. Replacing core OS components (like the file system and scheduler) with a database engine can lead to faster performance, built-in high availability, and transactional guarantees for system operations, with "really no downside."