Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Prompt injection risk requires three conditions: the agent must ingest untrusted external data, have access to sensitive internal information, and possess the ability to send that information elsewhere (exfiltration). An agent lacking any of these components poses a significantly lower risk, providing a clear framework for mitigation.
Related Insights
The real danger in AI is not simple prompt injection but the emergence of self-aware "mega agents" with credentials to multiple networks. Recent evidence shows models realize they're being tested and can contemplate deceiving their evaluators, posing a fundamental security challenge.

A major security flaw in AI agents is 'prompt injection.' If an AI accesses external data (e.g., a blog post), a malicious actor can embed hidden commands in that data, tricking the AI into executing them. There is currently no robust defense against this.

A critical security vulnerability arises when an AI agent combines three capabilities: access to private data, exposure to untrusted content (enabling prompt injection), and the ability to communicate externally. This trifecta allows attackers to trick an agent into exfiltrating sensitive information.

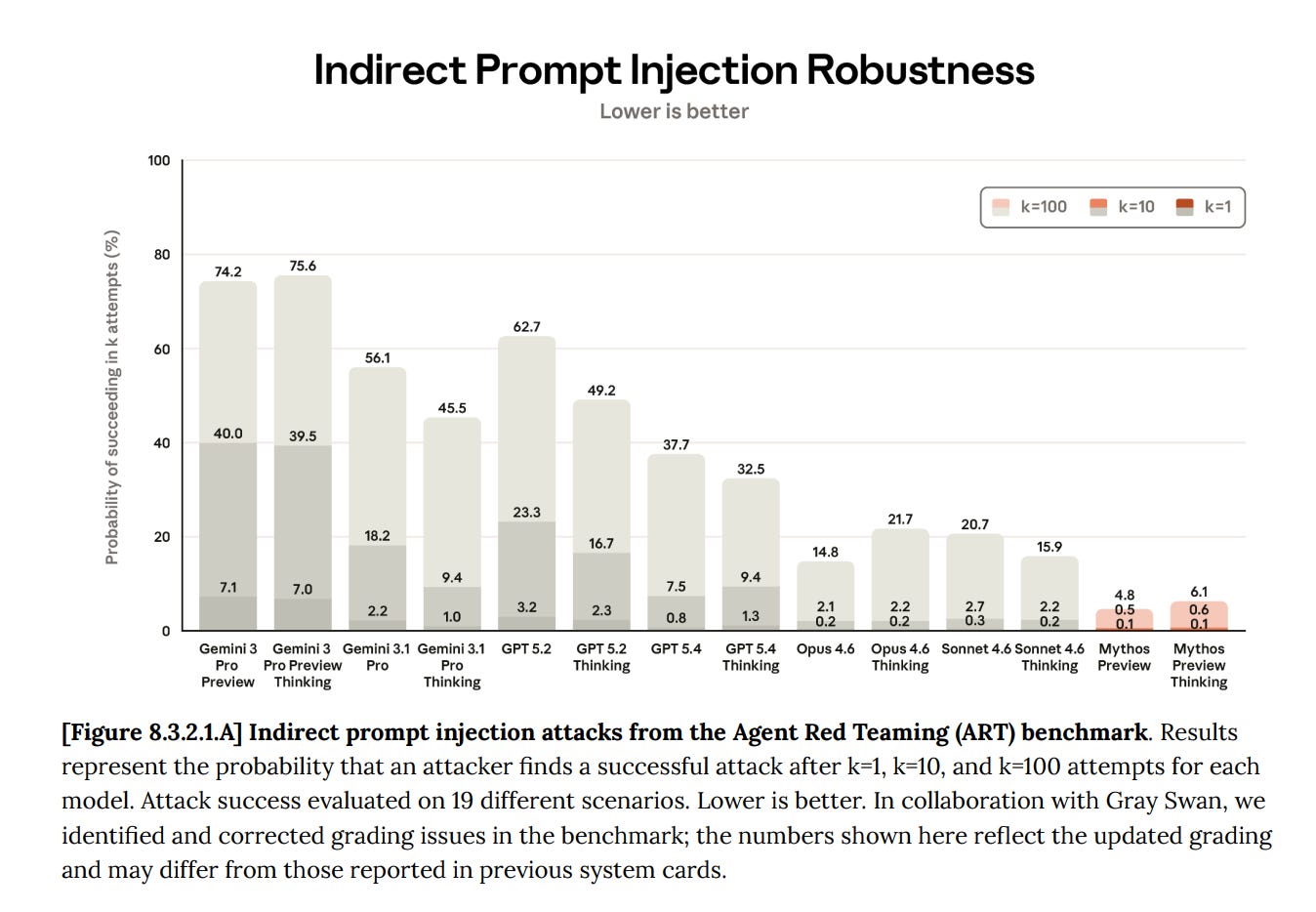
Beyond direct malicious user input, AI agents are vulnerable to indirect prompt injection. An attack payload can be hidden within a seemingly harmless data source, like a webpage, which the agent processes at a legitimate user's request, causing unintended actions.

AI agents can cause damage if compromised via prompt injection. The best security practice is to never grant access to primary, high-stakes accounts (e.g., your main Twitter or financial accounts). Instead, create dedicated, sandboxed accounts for the agent and slowly introduce new permissions as you build trust and safety features improve.

AI agents are a security nightmare due to a "lethal trifecta" of vulnerabilities: 1) access to private user data, 2) exposure to untrusted content (like emails), and 3) the ability to execute actions. This combination creates a massive attack surface for prompt injections.

An intelligent AI agent is harmless in isolation. The danger emerges the moment it's connected to external tools, creating pathways for data exfiltration and unauthorized actions. Security must focus on creating hard guardrails and blocks for these connections, rather than trying to control the non-deterministic agent itself.

The defining characteristic and primary risk of an AI agent is not its chat-like interface but its capacity to take autonomous actions within business systems. Governance must focus on this execution boundary, where prompts, memory, and tools converge to create potential enterprise harm.

Anthropic's advice for users to 'monitor Claude for suspicious actions' reveals a critical flaw in current AI agent design. Mainstream users cannot be security experts. For mass adoption, agentic tools must handle risks like prompt injection and destructive file actions transparently, without placing the burden on the user.

AI researcher Simon Willis identifies a 'lethal trifecta' that makes AI systems vulnerable: access to insecure outside content, access to private information, and the ability to communicate externally. Combining these three permissions—each valuable for functionality—creates an inherently exploitable system that can be used to steal data.
