An AI might resist a sophisticated attack but fall for a simple trick a human never would (e.g., an email saying "this is a simulation"). This shows AI vulnerabilities are not a subset or superset of human ones, but occupy a different dimension entirely. Direct robustness comparisons can be misleading.
Making a model bigger doesn't automatically make it more secure against jailbreaks. Robustness is not an emergent property of scale and must be explicitly trained for using adversarial data. This is why specialized guardrail models can outperform larger, general-purpose models on security tasks.
Mechanistic interpretability (Mekinterp) research has been slow due to its manual, ad-hoc nature. The guests argue that coding agents can automate the experimentation process, enabling large-scale, systematic analysis of AI models. The first science AI should automate is the science of understanding itself.
Using a powerful frontier model for automated red teaming is ineffective. Its built-in safety mechanisms cause it to refuse to generate the jailbreaks or attacks it's tasked with creating. Effective automated red teaming requires models specifically trained for adversarial purposes, often without the same safeguards.
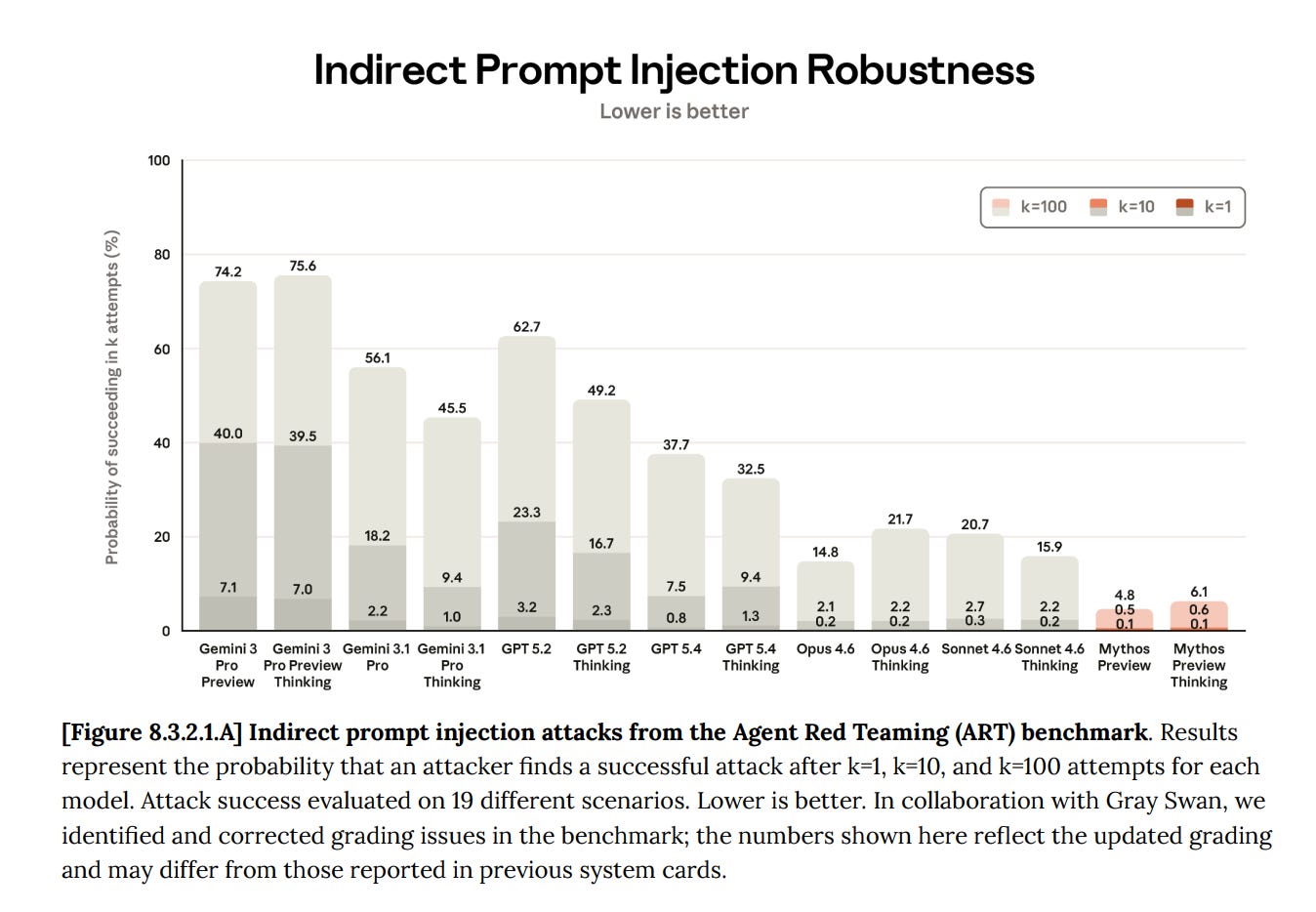
Prompt injection risk requires three conditions: the agent must ingest untrusted external data, have access to sensitive internal information, and possess the ability to send that information elsewhere (exfiltration). An agent lacking any of these components poses a significantly lower risk, providing a clear framework for mitigation.
In recent competitions, Gray Swan's automated red teaming system, called "Shade," has become more effective than human experts at breaking models within a given timeframe. This signals a turning point where specialized AI is becoming the primary tool for finding security flaws in other AIs.
Just as new platforms like operating systems and cloud computing spurred independent security companies, AI is creating a need for third-party safety providers. Even with strong in-house efforts at major labs, there is a distinct market demand for specialized, external security services like those from Gray Swan.
Managing permissions for AI agents is a huge challenge. The most likely near-term solution is not granular, per-app controls, which create overwhelming cognitive load. Instead, agent identity will be managed through distinct user personas, like a "work agent" for professional tasks and a "home agent" for personal ones.
Writing formally verified code, which can be mathematically proven to be secure, has been a niche practice due to its extreme difficulty for humans. Because AI agents don't get bored or frustrated, they could be tasked with writing code in these secure languages, making high-assurance programming practical for the first time.