Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Instead of a generic code review, use multiple AI agents with distinct personas (e.g., security expert, performance engineer, an opinionated developer like DHH). This simulates a diverse review panel, catching a wider range of potential issues and improvements.

Related Insights
To build a useful multi-agent AI system, model the agents after your existing human team. Create specialized agents for distinct roles like 'approvals,' 'document drafting,' or 'administration' to replicate and automate a proven workflow, rather than designing a monolithic, abstract AI.

Go beyond static AI code analysis. After an AI like Codex automatically flags a high-confidence issue in a GitHub pull request, developers can reply directly in a comment, "Hey, Codex, can you fix it?" The agent will then attempt to fix the issue it found.

To overcome the challenge of reviewing AI-generated code, have different LLMs like Claude and Codex review the code. Then, use a "peer review" prompt that forces the primary LLM to defend its choices or fix the issues raised by its "peers." This adversarial process catches more bugs and improves overall code quality.

Prompting a different LLM model to review code generated by the first one provides a powerful, non-defensive critique. This "second opinion" can rapidly identify architectural issues, bugs, and alternative approaches without the human ego involved in traditional code reviews.

Solo developers can integrate AI tools like BugBot with GitHub to automatically review pull requests. These specialized AIs are trained to find security vulnerabilities and bugs that a solo builder might miss, providing a crucial safety net and peace of mind.

To improve the quality and accuracy of an AI agent's output, spawn multiple sub-agents with competing or adversarial roles. For example, a code review agent finds bugs, while several "auditor" agents check for false positives, resulting in a more reliable final analysis.

Separating AI agents into distinct roles (e.g., a technical expert and a customer-facing communicator) mirrors real-world team specializations. This allows for tailored configurations, like different 'temperature' settings for creativity versus accuracy, improving overall performance and preventing role confusion.

Instead of relying on a single, all-purpose coding agent, the most effective workflow involves using different agents for their specific strengths. For example, using the 'Friday' agent for UI tasks, 'Charlie' for code reviews, and 'Claude Code' for research and backend logic.
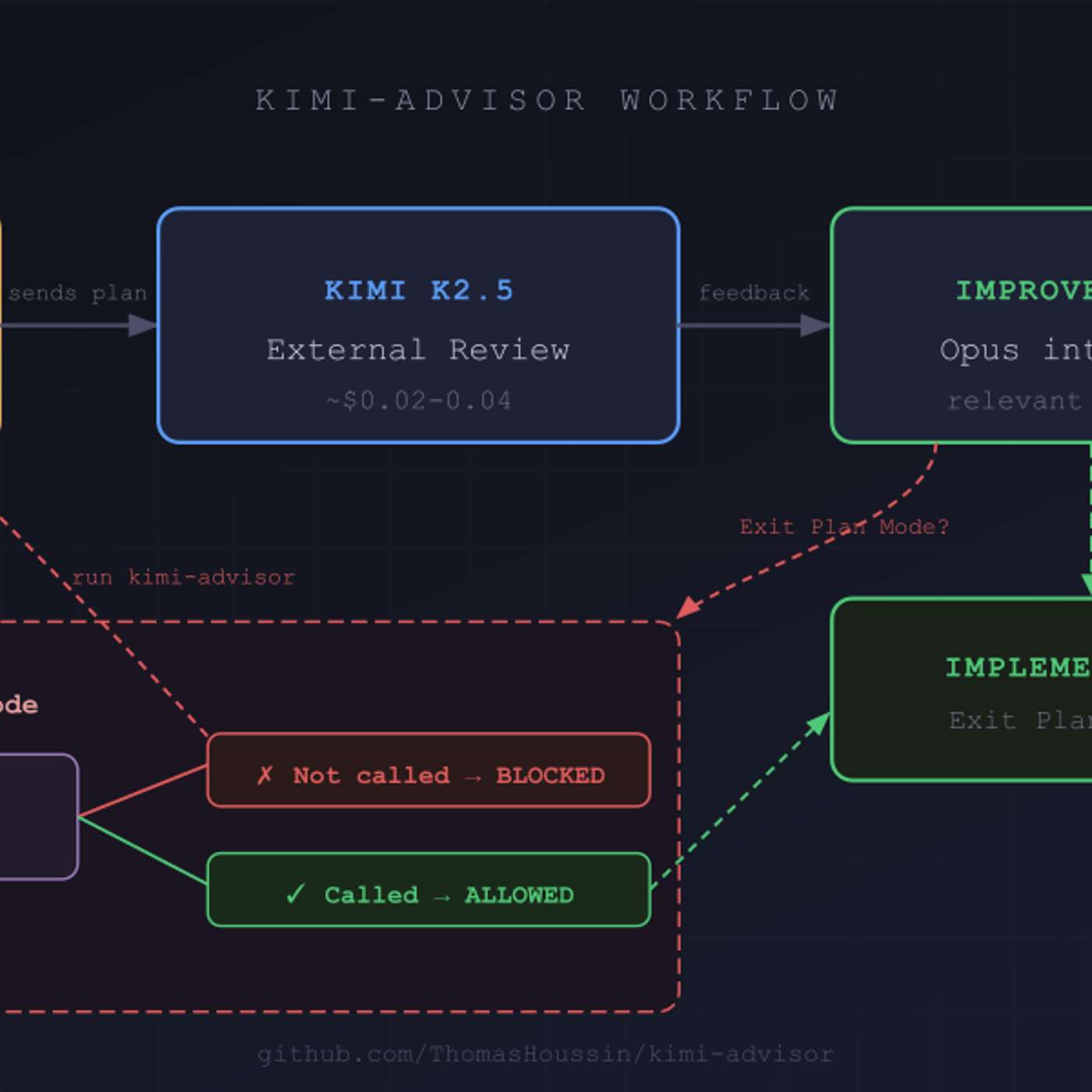
To improve code quality, use a secondary AI model from a different provider (e.g., Moonshot AI's Kimi) to review plans generated by a primary model (e.g., Anthropic's Claude). This introduces cognitive diversity and avoids the shared biases inherent in a single model family, leading to a more robust and enriching review process.
Define different agents (e.g., Designer, Engineer, Executive) with unique instructions and perspectives, then task them with reviewing a document in parallel. This generates diverse, structured feedback that mimics a real-world team review, surfacing potential issues from multiple viewpoints simultaneously.
