Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
By understanding that XMP metadata resides at the beginning of an image file, the solution reads only the first 64KB. This avoids processing the entire multi-megabyte file, creating a near-instantaneous check with minimal resource usage, even for very large images.

Related Insights
This model is explicitly optimized for speed in production environments, distinguishing it from slower, experimental tools. This focus on performance makes it ideal for commercial applications like marketing and content creation, where rapid iteration and high-volume asset generation are critical for efficiency.

To overcome AI's tendency for generic descriptions of archival images, Tim McLear's scripts first extract embedded metadata (location, date). This data is then included in the prompt, acting as a "source of truth" that guides the AI to produce specific, verifiable outputs instead of just guessing based on visual content.

To move beyond keyword search in their media archive, Tim McLear's system generates two vector embeddings for each asset: one from the image thumbnail and another from its AI-generated text description. Fusing these enables a powerful semantic search that understands visual similarity and conceptual relationships, not just exact text matches.
Instead of building a resource-intensive AI image classifier, the developer discovered major AI tools embed provenance data using open standards like C2PA and XMP. A simple metadata parser was sufficient, eliminating the need for a complex ML pipeline and delivering a zero-cost solution.
When building AI workflows that process non-text files like PDFs or HTML, consider using Google's Gemini models. They are specifically strong at ingesting and analyzing various file types, often outperforming other major models for these specific use cases.

A critical failure point for C2PA is that social media platforms themselves can inadvertently strip the crucial metadata during their standard image and video processing pipelines. This technical flaw breaks the chain of provenance before the content is even displayed to users.
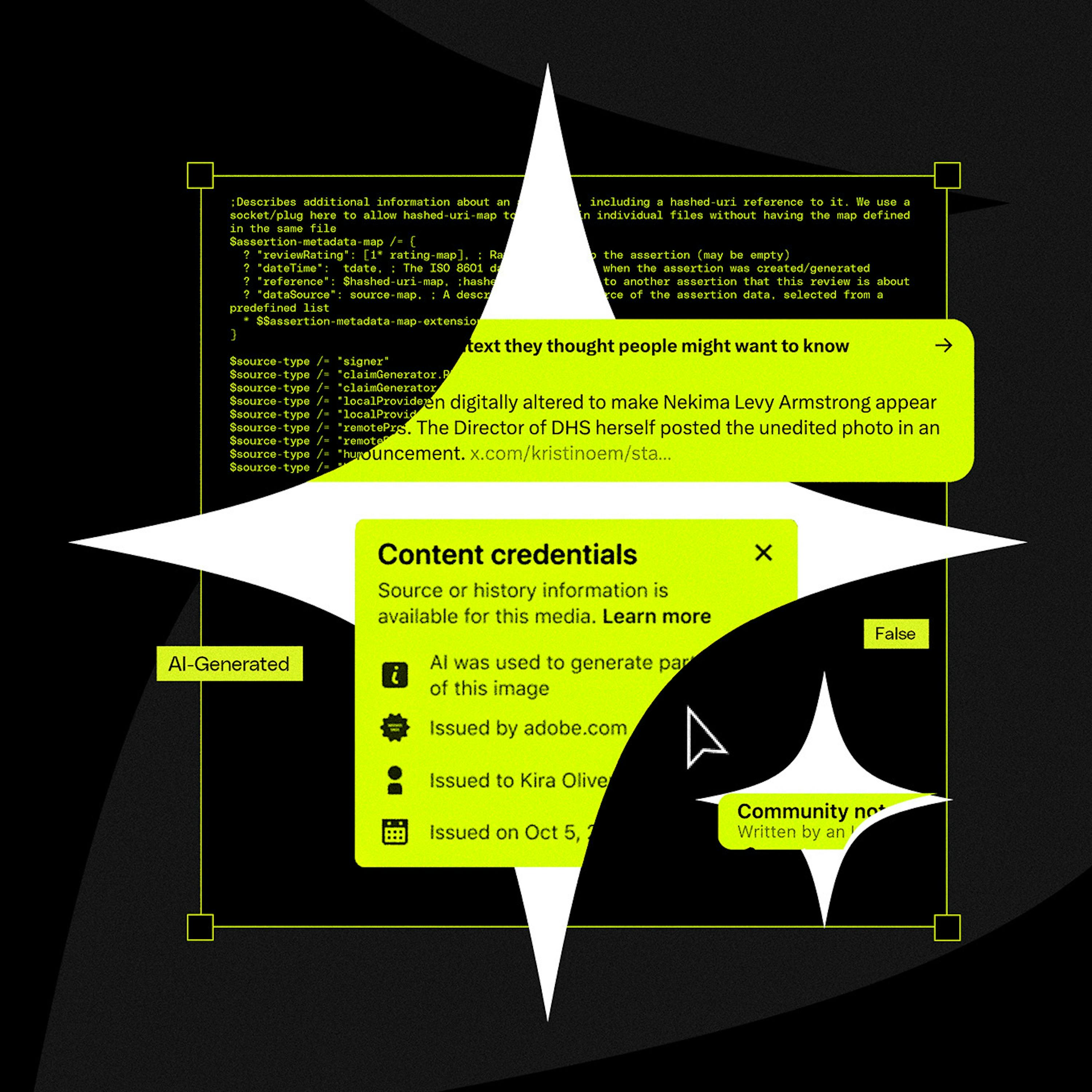
The official C2PA library offered full cryptographic verification of AI image origins. However, for a simple transparency badge, simply checking for the existence of a metadata field was sufficient. This avoided a large 1.5MB library and unnecessary processing for the specific product use case.
When using an LLM for data enrichment, giving it a long list of items to extract (e.g., inventory, images, features) results in low-quality output. A more effective method is to run separate, sequential passes for each data point, which improves accuracy and allows you to handle edge cases between steps.

Instead of storing AI-generated descriptions in a separate database, Tim McLear's "Flip Flop" app embeds metadata directly into each image file's EXIF data. This makes each file a self-contained record where rich context travels with the image, accessible by any system or person, regardless of access to the original database.
The AI detection logic is only loaded when a user interacts with the image uploader, keeping the initial app bundle small and fast. Furthermore, if the detection process fails, it does so silently without impacting the user experience—a robust pattern for non-essential enhancements.