Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Unlike approaches using separate specialized models (like Mixture-of-Experts), Mistral-Medium-3.5 employs a dense, "merged" architecture. This single 128B parameter system consolidates diverse capabilities into a unified framework, simplifying deployment and ensuring consistent performance across different task types without needing to switch models.

Related Insights
Instead of interacting with a single LLM, users will increasingly call an API that represents a "system as a model." Behind the scenes, this triggers a complex orchestration of multiple specialized models, sub-agents, and tools to complete a task, while maintaining a simple user experience.

The path to robust AI applications isn't a single, all-powerful model. It's a system of specialized "sub-agents," each handling a narrow task like context retrieval or debugging. This architecture allows for using smaller, faster, fine-tuned models for each task, improving overall system performance and efficiency.

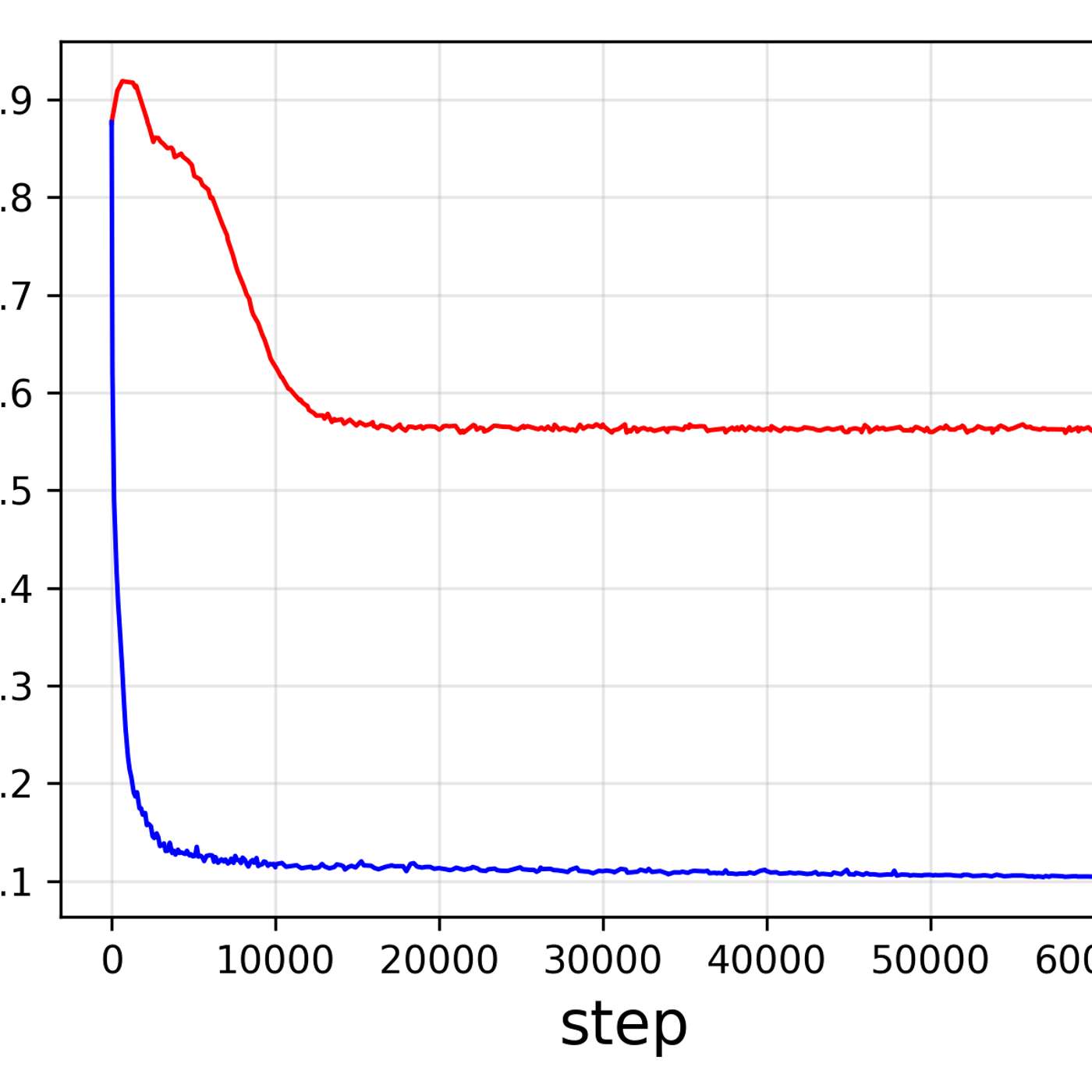
The model uses a Mixture-of-Experts (MoE) architecture with over 200 billion parameters, but only activates a "sparse" 10 billion for any given task. This design provides the knowledge base of a massive model while keeping inference speed and cost comparable to much smaller models.

Breakthroughs will emerge from 'systems' of AI—chaining together multiple specialized models to perform complex tasks. GPT-4 is rumored to be a 'mixture of experts,' and companies like Wonder Dynamics combine different models for tasks like character rigging and lighting to achieve superior results.

Instead of a single "omni-model," Mistral offers both large, general-purpose models and smaller, highly optimized models for specific tasks like transcription. This allows customers to choose a cost-effective solution for dedicated use cases without paying for unneeded capabilities.
Mistral-Medium-3.5 allows users to adjust its "reasoning effort" per request. This unique feature enables the same model weights to deliver either quick responses for simple queries or perform extended computation for complex agentic tasks, optimizing the trade-off between latency and solution quality.
Mistral's R&D strategy involves dedicated teams focusing on single capabilities like coding (Devstral) or vision (PixTravel). Once these specialized models mature, their functionalities are merged into a unified, more powerful mixture-of-experts model like "Mistral Small".
Unlike single-provider tools, Perplexity Computer orchestrates multiple AI models (Sonnet, Gemini, Opus) for different sub-tasks like planning, coding, and reasoning. This ensemble approach reduces the frustrating re-prompting loop and yields better results from a single initial prompt.

Powerful AI tools are becoming aggregators like Manus, which intelligently select the best underlying model for a specific task—research, data visualization, or coding. This multi-model approach enables a seamless workflow within a single thread, outperforming systems reliant on one general-purpose model.

Adopting a single, unified architecture for both vision and generation tasks simplifies the engineering lifecycle. This approach reduces the cost and complexity of maintaining, updating, and deploying multiple specialized models, accelerating development.