Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
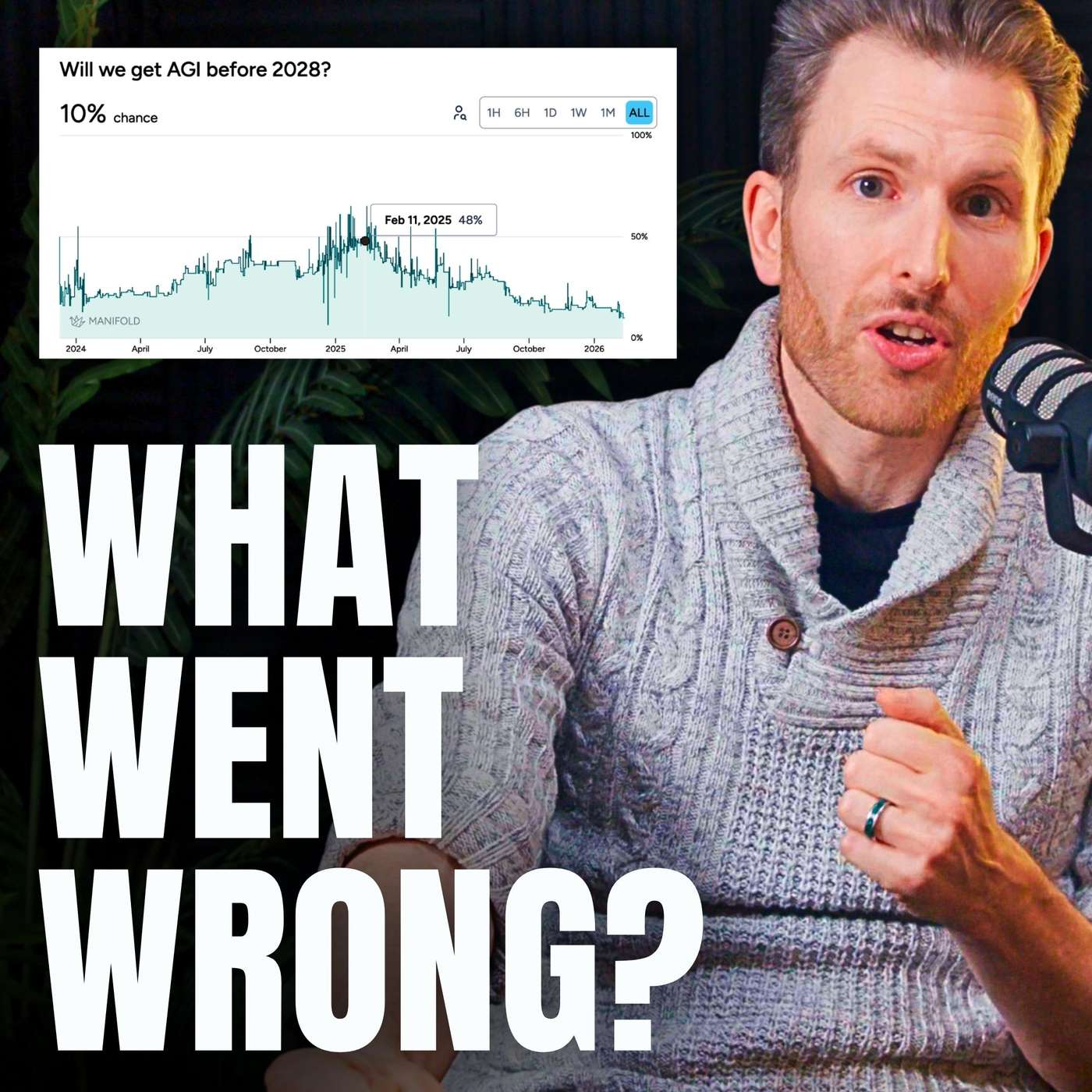
Hopes that AI's new reasoning skills in checkable domains like math and code would generalize to ambiguous, real-world tasks like booking a flight did not materialize. This failure of 'reasoning generalization' was a major technical roadblock that forced experts to lengthen AGI timelines.
Related Insights
AI models struggle to plan at different levels of abstraction simultaneously. They can't easily move from a high-level goal to a detailed task and then back up to adjust the high-level plan if the detail is blocked, a key aspect of human reasoning.

When AI models achieve superhuman performance on specific benchmarks like coding challenges, it doesn't solve real-world problems. This is because we implicitly optimize for the benchmark itself, creating "peaky" performance rather than broad, generalizable intelligence.
![[State of RL/Reasoning] IMO/IOI Gold, OpenAI o3/GPT-5, and Cursor Composer — Ashvin Nair, Cursor thumbnail](https://assets.flightcast.com/V2Uploads/nvaja2542wefzb8rjg5f519m/01K4D8FB4MNA071BM5ZDSMH34N/square.jpg)
There's a significant gap between AI performance in simulated benchmarks and in the real world. Despite scoring highly on evaluations, AIs in real deployments make "silly mistakes that no human would ever dream of doing," suggesting that current benchmarks don't capture the messiness and unpredictability of reality.

Instead of a single, generalizable AI, we are creating 'Functional AGI'—a collection of specialized AIs layered together. This system will feel like AGI to users but lacks true cross-domain reasoning, as progress in one area (like coding) doesn't translate to others (like history).

Current AI models resemble a student who grinds 10,000 hours on a narrow task. They achieve superhuman performance on benchmarks but lack the broad, adaptable intelligence of someone with less specific training but better general reasoning. This explains the gap between eval scores and real-world utility.

Demis Hassabis explains that current AI models have 'jagged intelligence'—performing at a PhD level on some tasks but failing at high-school level logic on others. He identifies this lack of consistency as a primary obstacle to achieving true Artificial General Intelligence (AGI).

The current focus on pre-training AI with specific tool fluencies overlooks the crucial need for on-the-job, context-specific learning. Humans excel because they don't need pre-rehearsal for every task. This gap indicates AGI is further away than some believe, as true intelligence requires self-directed, continuous learning in novel environments.

Demis Hassabis identifies a key obstacle for AGI. Unlike in math or games where answers can be verified, the messy real world lacks clear success metrics. This makes it difficult for AI systems to use self-improvement loops, limiting their ability to learn and adapt outside of highly structured domains.

The central challenge for current AI is not merely sample efficiency but a more profound failure to generalize. Models generalize 'dramatically worse than people,' which is the root cause of their brittleness, inability to learn from nuanced instruction, and unreliability compared to human intelligence. Solving this is the key to the next paradigm.

Replit's CEO argues that today's LLMs are asymptoting on general reasoning tasks. Progress continues only in domains with binary outcomes, like coding, where synthetic data can be generated infinitely. This indicates a fundamental limitation of the current 'ingest the internet' approach for achieving AGI.