Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Like human experts, advanced AI models improve their answers the more time they spend on a problem. This 'inference scaling' means short evaluations may fail to capture a model's true capabilities, as performance continues to increase with more computation, making it difficult to establish a performance ceiling.

Related Insights
A 10x increase in compute may only yield a one-tier improvement in model performance. This appears inefficient but can be the difference between a useless "6-year-old" intelligence and a highly valuable "16-year-old" intelligence, unlocking entirely new economic applications.
![Dylan Patel - Inside the Trillion-Dollar AI Buildout - [Invest Like the Best, EP.442] thumbnail](https://megaphone.imgix.net/podcasts/799253cc-9de9-11f0-8661-ab7b8e3cb4c1/image/d41d3a6f422989dc957ef10da7ad4551.jpg?ixlib=rails-4.3.1&max-w=3000&max-h=3000&fit=crop&auto=format,compress)
AI intelligence shouldn't be measured with a single metric like IQ. AIs exhibit "jagged intelligence," being superhuman in specific domains (e.g., mastering 200 languages) while simultaneously lacking basic capabilities like long-term planning, making them fundamentally unlike human minds.

"Amortized inference" bakes slow, deliberative reasoning into a fast, single-pass model. While the brain uses a mix, digital minds have a strong incentive to amortize more capabilities. This is because once a capability is baked in, the resulting model can be copied infinitely, unlike a biological brain.

While the 'time horizon' metric effectively tracks AI capability, it's unclear at what point it signals danger. Researchers don't know if the critical threshold for AI-driven R&D acceleration is a 40-hour task, a week-long task, or something else. This gap makes it difficult to translate current capability measurements into a concrete risk timeline.

Over two-thirds of reasoning models' performance gains came from massively increasing their 'thinking time' (inference scaling). This was a one-time jump from a zero baseline. Further gains are prohibitively expensive due to compute limitations, meaning this is not a repeatable source of progress.
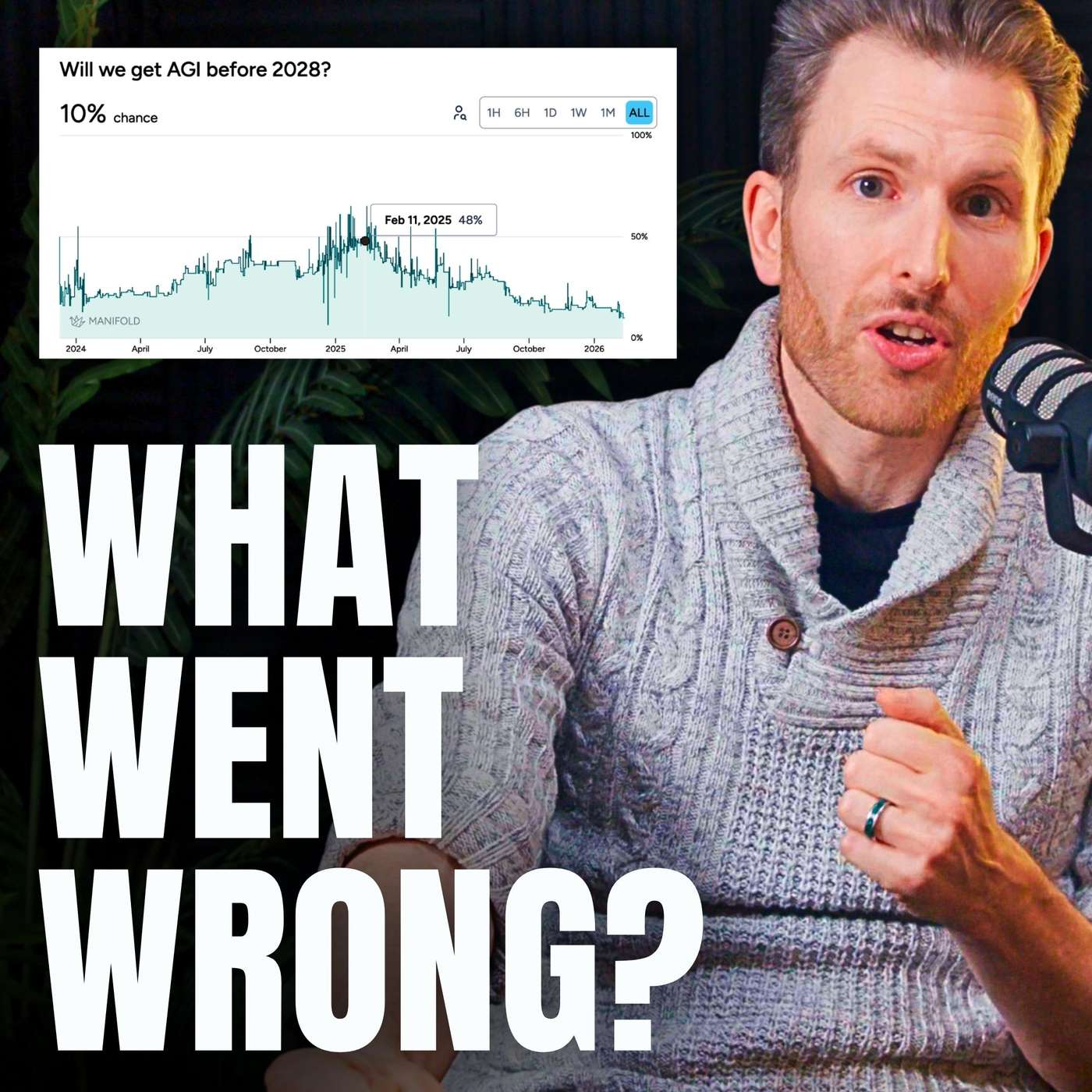
AI struggles with long-horizon tasks not just due to technical limits, but because we lack good ways to measure performance. Once effective evaluations (evals) for these capabilities exist, researchers can rapidly optimize models against them, accelerating progress significantly.

Current AI models resemble a student who grinds 10,000 hours on a narrow task. They achieve superhuman performance on benchmarks but lack the broad, adaptable intelligence of someone with less specific training but better general reasoning. This explains the gap between eval scores and real-world utility.

Benchmarking reasoning models revealed no clear correlation between the level of reasoning and an LLM's performance. In fact, even when there is a slight accuracy gain (1-2%), it often comes with a significant cost increase, making it an inefficient trade-off.

Third-party tracker METR observed that model complexity was doubling every seven months. However, a recent proprietary model shattered this trend, demonstrating nearly double the expected capability for independent operation (15 hours vs. an expected 8). This signals that AI advancement is accelerating unpredictably, outpacing prior scaling laws.

A major challenge for the 'time horizon' metric is its cost. As AI capabilities improve, the tasks needed to benchmark them grow from hours to weeks or months. The cost of paying human experts for these long durations to establish a baseline becomes extremely high, threatening the long-term viability of this evaluation method.