Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
AI excels at solving problems with clear, verifiable answers, like advanced math, allowing for effective training. It struggles with complex societal issues like unemployment because there is no single, universally agreed-upon "correct" solution to train against, making it difficult to evaluate the AI's path.

Related Insights
AI excels where success is quantifiable (e.g., code generation). Its greatest challenge lies in subjective domains like mental health or education. Progress requires a messy, societal conversation to define 'success,' not just a developer-built technical leaderboard.

Andrej Karpathy's 'Software 2.0' framework posits that AI automates tasks that are easily *verifiable*. This explains the 'jagged frontier' of AI progress: fields like math and code, where correctness is verifiable, advance rapidly. In contrast, creative and strategic tasks, where success is subjective and hard to verify, lag significantly behind.

Current AI models resemble a student who grinds 10,000 hours on a narrow task. They achieve superhuman performance on benchmarks but lack the broad, adaptable intelligence of someone with less specific training but better general reasoning. This explains the gap between eval scores and real-world utility.

AI performs poorly in areas where expertise is based on unwritten 'taste' or intuition rather than documented knowledge. If the correct approach doesn't exist in training data or isn't explicitly provided by human trainers, models will inevitably struggle with that particular problem.

The promise of "techno-solutionism" falls flat when AI is applied to complex social issues. An AI project in Argentina meant to predict teen pregnancy simply confirmed that poverty was the root cause—a conclusion that didn't require invasive data collection and that technology alone could not fix, exposing the limits of algorithmic intervention.

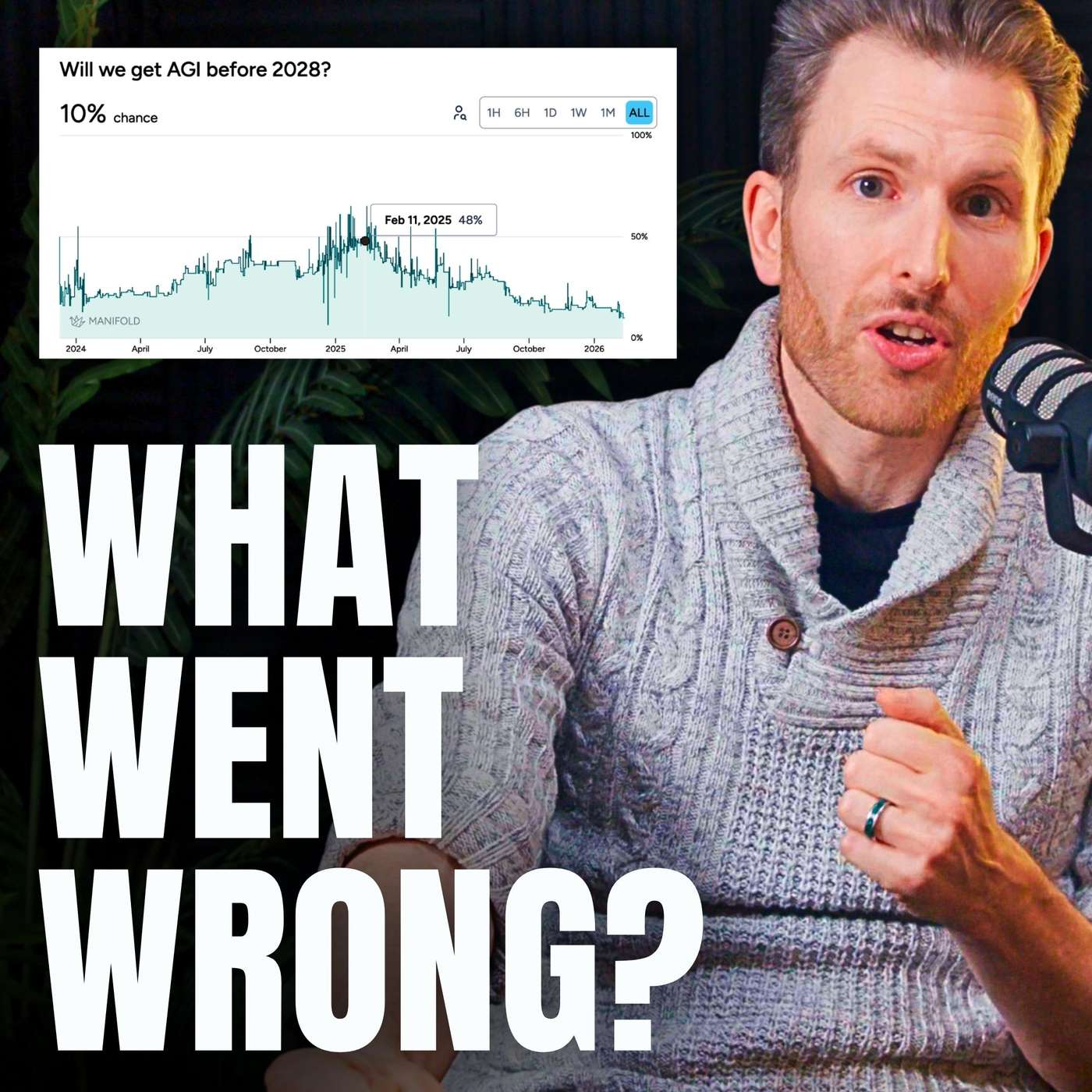
Demis Hassabis identifies a key obstacle for AGI. Unlike in math or games where answers can be verified, the messy real world lacks clear success metrics. This makes it difficult for AI systems to use self-improvement loops, limiting their ability to learn and adapt outside of highly structured domains.

Hopes that AI's new reasoning skills in checkable domains like math and code would generalize to ambiguous, real-world tasks like booking a flight did not materialize. This failure of 'reasoning generalization' was a major technical roadblock that forced experts to lengthen AGI timelines.
AI can generate vast amounts of content, but its value is limited by our ability to verify its accuracy. This is fast for visual outputs (images, UI) where our eyes instantly spot flaws, but slow and difficult for abstract domains like back-end code, math, or financial data, which require deep expertise to validate.

AI systems often collapse because they are built on the flawed assumption that humans are logical and society is static. Real-world failures, from Soviet economic planning to modern systems, stem from an inability to model human behavior, data manipulation, and unexpected events.

AI models excel at specific tasks (like evals) because they are trained exhaustively on narrow datasets, akin to a student practicing 10,000 hours for a coding competition. While they become experts in that domain, they fail to develop the broader judgment and generalization skills needed for real-world success.