Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
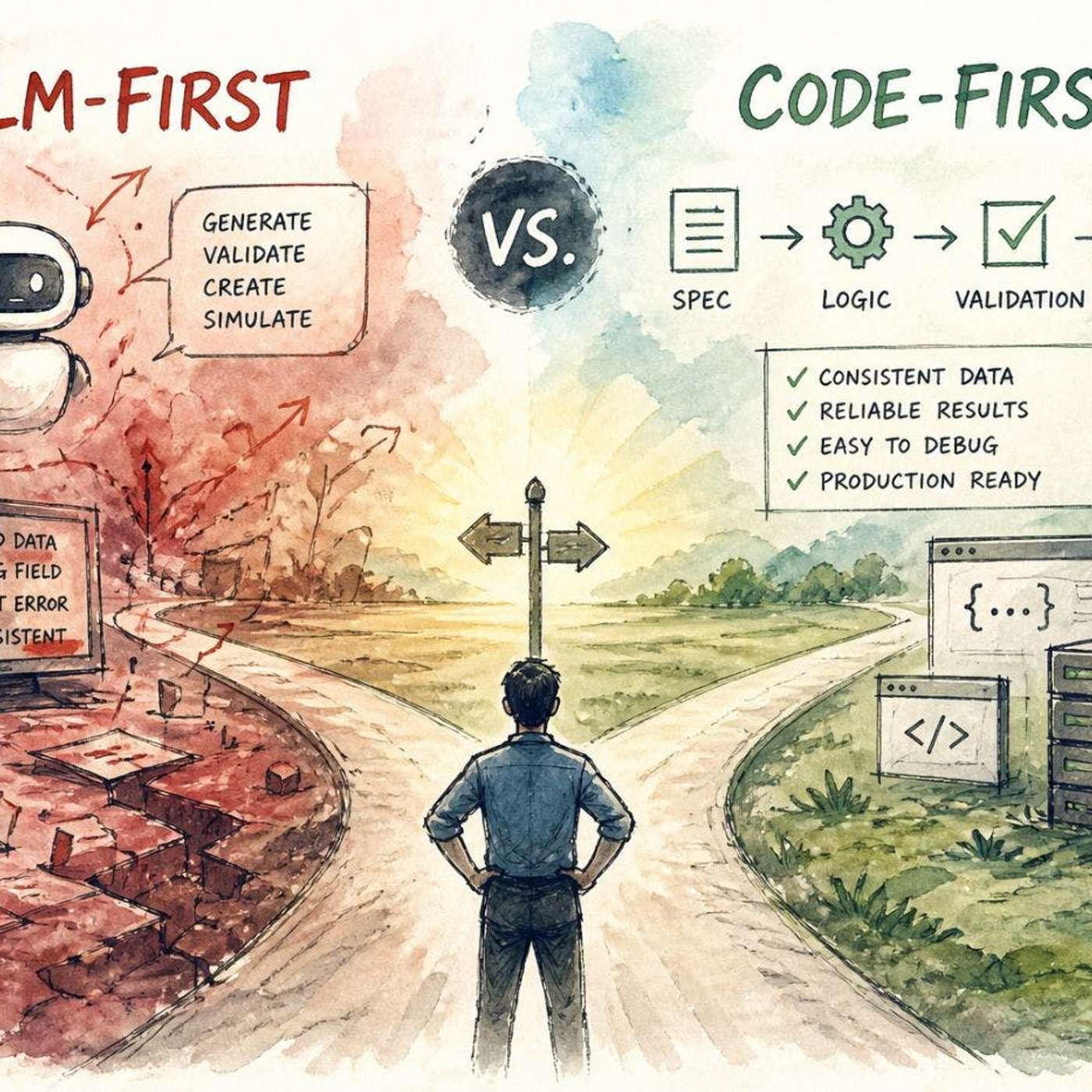
An 'LLM-first' approach, where the model handles core logic, creates impressive demos but lacks production reliability. A 'code-first' approach, using code for structure and LLMs for specific tasks, is less flashy but proves robust and debuggable in real-world applications.
Related Insights
Many AI developers get distracted by the 'LLM hype,' constantly chasing the best-performing model. The real focus should be on solving a specific customer problem. The LLM is a component, not the product, and deterministic code or simpler tools are often better for certain tasks.

A practical hack to improve AI agent reliability is to avoid built-in tool-calling functions. LLMs have more training data on writing code than on specific tool-use APIs. Prompting the agent to write and execute the code that calls a tool leverages its core strength and produces better outcomes.

LLMs shine when acting as a 'knowledge extruder'—shaping well-documented, 'in-distribution' concepts into specific code. They fail when the core task is novel problem-solving where deep thinking, not code generation, is the bottleneck. In these cases, the code is the easy part.

Don't give LLMs full control. Use deterministic code for core logic, validation, and enforcing rules. Delegate only tasks requiring flexibility or understanding of unstructured input to the LLM, treating it as a specialized component, not the entire system.
High productivity isn't about using AI for everything. It's a disciplined workflow: breaking a task into sub-problems, using an LLM for high-leverage parts like scaffolding and tests, and reserving human focus for the core implementation. This avoids the sunk cost of forcing AI on unsuitable tasks.
Separate AI's role. Use an AI assistant to write reliable, deterministic code for structuring data (e.g., pulling Slack messages via API). Then, apply a live AI model only for the subjective task, like categorizing message urgency. This hybrid approach creates a more robust and controllable system.

LLMs in production don't often crash spectacularly. Instead, they introduce subtle, probabilistic errors—like incorrect enum values or missing fields—that are hard to debug because they lack clear error patterns, unlike deterministic code failures.
AI-driven code generation relies on design systems for instructions. A weak system leads to poor code output, making the design system a critical foundation for engineering quality and speed, not just a design team's responsibility.

To get the best results from AI code generation platforms, first use a conversational LLM like Claude to brainstorm and write a detailed product spec. This two-step process—spec generation then code generation—improves the final output and reduces costly iterations with the coding agent.

To improve LLM reasoning, researchers feed them data that inherently contains structured logic. Training on computer code was an early breakthrough, as it teaches patterns of reasoning far beyond coding itself. Textbooks are another key source for building smaller, effective models.
