Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
While the theories behind neural networks existed for decades, their practical application was infeasible. The true catalyst wasn't a new algorithm, but the parallel processing power of GPUs and the availability of massive datasets, which finally made training complex models a reality.
Related Insights
The 2012 breakthrough that ignited the modern AI era used the ImageNet dataset, a novel neural network, and only two NVIDIA gaming GPUs. This demonstrates that foundational progress can stem from clever architecture and the right data, not just massive initial compute power, a lesson often lost in today's scale-focused environment.

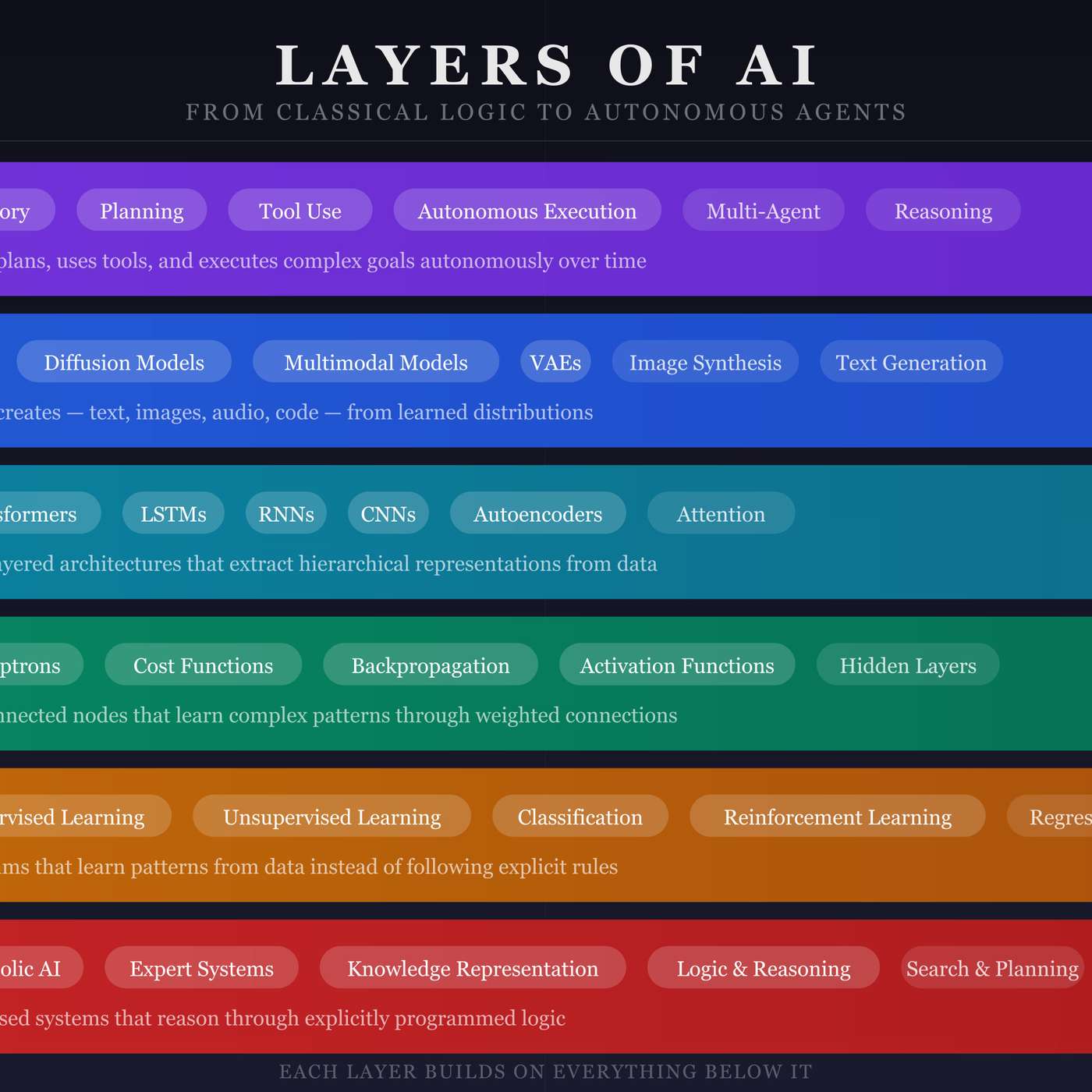
The progress in deep learning, from AlexNet's GPU leap to today's massive models, is best understood as a history of scaling compute. This scaling, resulting in a million-fold increase in power, enabled the transition from text to more data-intensive modalities like vision and spatial intelligence.

The progression from early neural networks to today's massive models is fundamentally driven by the exponential increase in available computational power, from the initial move to GPUs to today's million-fold increases in training capacity on a single model.

The computational power for modern AI wasn't developed for AI research. Massive consumer demand for high-end gaming GPUs created the powerful, parallel processing hardware that researchers later realized was perfect for training neural networks, effectively subsidizing the AI boom.

A key surprise in AI development was the non-linear impact of scale. Sebastian Thrun noted that while AI trained on millions of documents is 'fine,' training it on hundreds of billions creates an 'unbelievably smart' system, shocking even its creators and demonstrating data volume as a primary driver of breakthroughs.

The history of AI, such as the 2012 AlexNet breakthrough, demonstrates that scaling compute and data on simpler, older algorithms often yields greater advances than designing intricate new ones. This "bitter lesson" suggests prioritizing scalability over algorithmic complexity for future progress.

The 2012 AlexNet breakthrough didn't use supercomputers but two consumer-grade Nvidia GeForce gaming GPUs. This "Big Bang" moment proved the value of parallel processing on GPUs for AI, pivoting Nvidia from a PC gaming company to the world's most valuable AI chipmaker, showing how massive industries can emerge from niche applications.

The "Attention is All You Need" paper's key breakthrough was an architecture designed for massive scalability across GPUs. This focus on efficiency, anticipating the industry's shift to larger models, was more crucial to its dominance than the attention mechanism itself.

Dr. Fei-Fei Li realized AI was stagnating not from flawed algorithms, but a missed scientific hypothesis. The breakthrough insight behind ImageNet was that creating a massive, high-quality dataset was the fundamental problem to solve, shifting the paradigm from being model-centric to data-centric.

The recent AI breakthrough wasn't just a new algorithm. It was the result of combining two massive quantitative shifts: internet-scale training data and 80 years of Moore's Law culminating in GPU power. This sheer scale created a qualitative leap in capability.