Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
For AI operating in the physical world, the goal isn't impossible perfection but perfect "explainability." Since systems will inevitably make mistakes, the ability to decompose an error, understand its root cause, and correct it is the most critical safety feature. Black-box outputs are unacceptable.

Related Insights
The need for explicit user transparency is most critical for nondeterministic systems like LLMs, where even creators don't always know why an output was generated. Unlike a simple rules engine with predictable outcomes, AI's "black box" nature requires giving users more context to build trust.

To build user trust in high-stakes AI, transparency is a core product feature, not an option. This means surfacing the AI's reasoning, showing its confidence levels, and making trade-offs visible. This clarity transforms the AI from a black box into a collaborative tool, bringing the user into the decision loop.

Contrary to fears that reinforcement learning would push models' internal reasoning (chain-of-thought) into an unexplainable shorthand, OpenAI has not seen significant evidence of this "neural ease." Models still predominantly use plain English for their internal monologue, a pleasantly surprising empirical finding that preserves a crucial method for safety research and interpretability.

To address safety concerns of an end-to-end "black box" self-driving AI, NVIDIA runs it in parallel with a traditional, transparent software stack. A "safety policy evaluator" then decides which system to trust at any moment, providing a fallback to a more predictable system in uncertain scenarios.

As AI models are used for critical decisions in finance and law, black-box empirical testing will become insufficient. Mechanistic interpretability, which analyzes model weights to understand reasoning, is a bet that society and regulators will require explainable AI, making it a crucial future technology.

The latest Full Self-Driving version likely eliminates traditional `if-then` coding for a pure neural network. This leap in performance comes at the cost of human auditability, as no one can truly understand *how* the AI makes its life-or-death decisions, marking a profound shift in software.

For an AI optimizing physical infrastructure like buildings, customer adoption hinges on explainability. Product leader John Boothroyd's team had to create visual representations showing how the AI made decisions to gain trust. This proves transparency is essential for automated systems with real-world consequences.

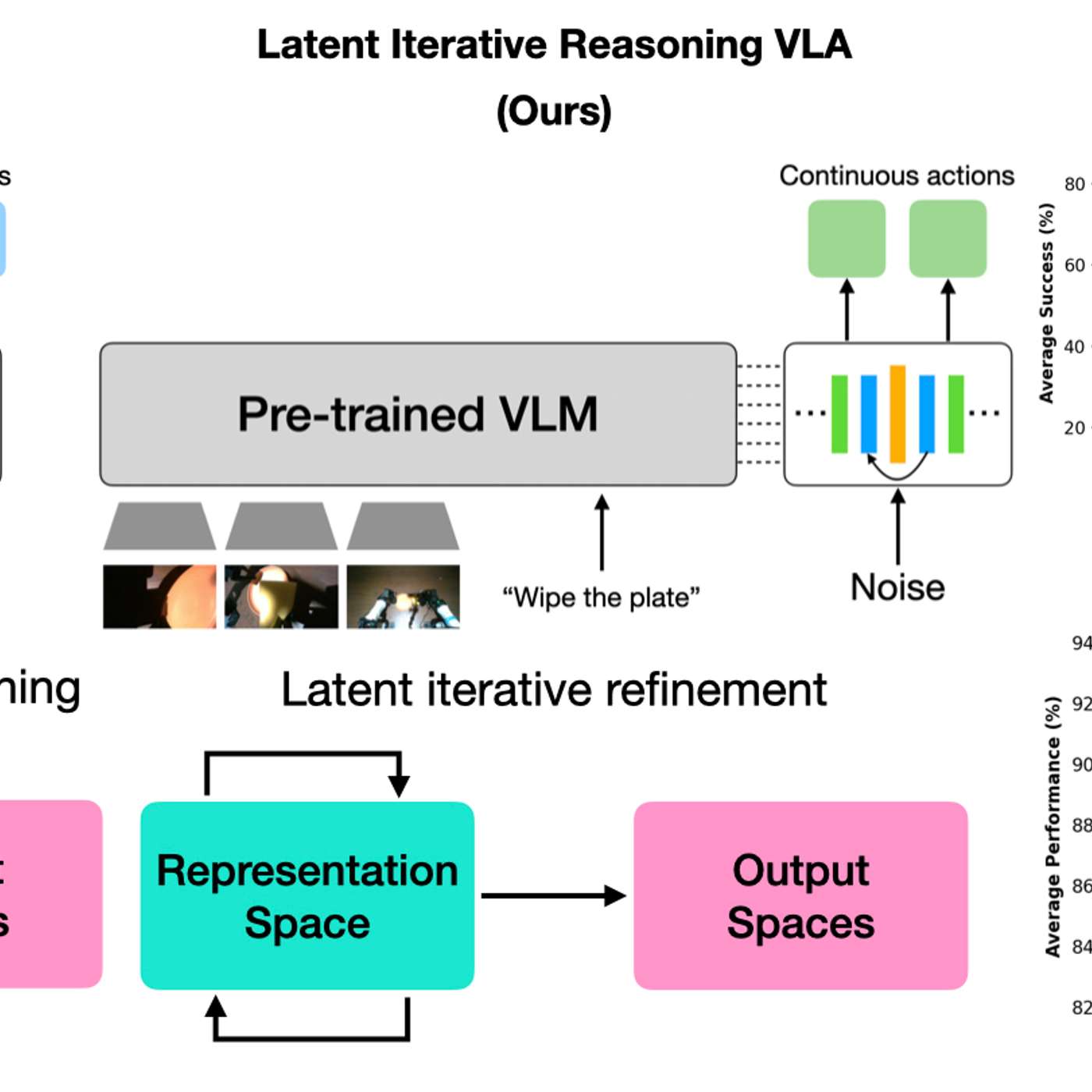
By having AI models 'think' in a hidden latent space, robots gain efficiency without generating slow, text-based reasoning. This creates a black box, making it impossible for humans to understand the robot's logic, which is a major concern for safety-critical applications where interpretability is crucial.
For AI systems to be adopted in scientific labs, they must be interpretable. Researchers need to understand the 'why' behind an AI's experimental plan to validate and trust the process, making interpretability a more critical feature than raw predictive power.

Efforts to understand an AI's internal state (mechanistic interpretability) simultaneously advance AI safety by revealing motivations and AI welfare by assessing potential suffering. The goals are aligned through the shared need to "pop the hood" on AI systems, not at odds.
