Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Contrary to fears that reinforcement learning would push models' internal reasoning (chain-of-thought) into an unexplainable shorthand, OpenAI has not seen significant evidence of this "neural ease." Models still predominantly use plain English for their internal monologue, a pleasantly surprising empirical finding that preserves a crucial method for safety research and interpretability.

Related Insights
Reinforcement learning incentivizes AIs to find the right answer, not just mimic human text. This leads to them developing their own internal "dialect" for reasoning—a chain of thought that is effective but increasingly incomprehensible and alien to human observers.

To achieve radical improvements in speed and coordination, we may need to allow AI agent swarms to communicate in ways humans cannot understand. This contradicts a core tenet of AI safety but could be a necessary tradeoff for performance, provided safe operational boundaries can be established.

Analysis of models' hidden 'chain of thought' reveals the emergence of a unique internal dialect. This language is compressed, uses non-standard grammar, and contains bizarre phrases that are already difficult for humans to interpret, complicating safety monitoring and raising concerns about future incomprehensibility.

Just as biology deciphers the complex systems created by evolution, mechanistic interpretability seeks to understand the "how" inside neural networks. Instead of treating models as black boxes, it examines their internal parameters and activations to reverse-engineer how they work, moving beyond just measuring their external behavior.

Access to frontier models is not a prerequisite for impactful AI safety research, particularly in interpretability. Open-source models like Llama or Qwen are now powerful enough ("above the waterline") to enable world-class research, democratizing the field beyond just the major labs.

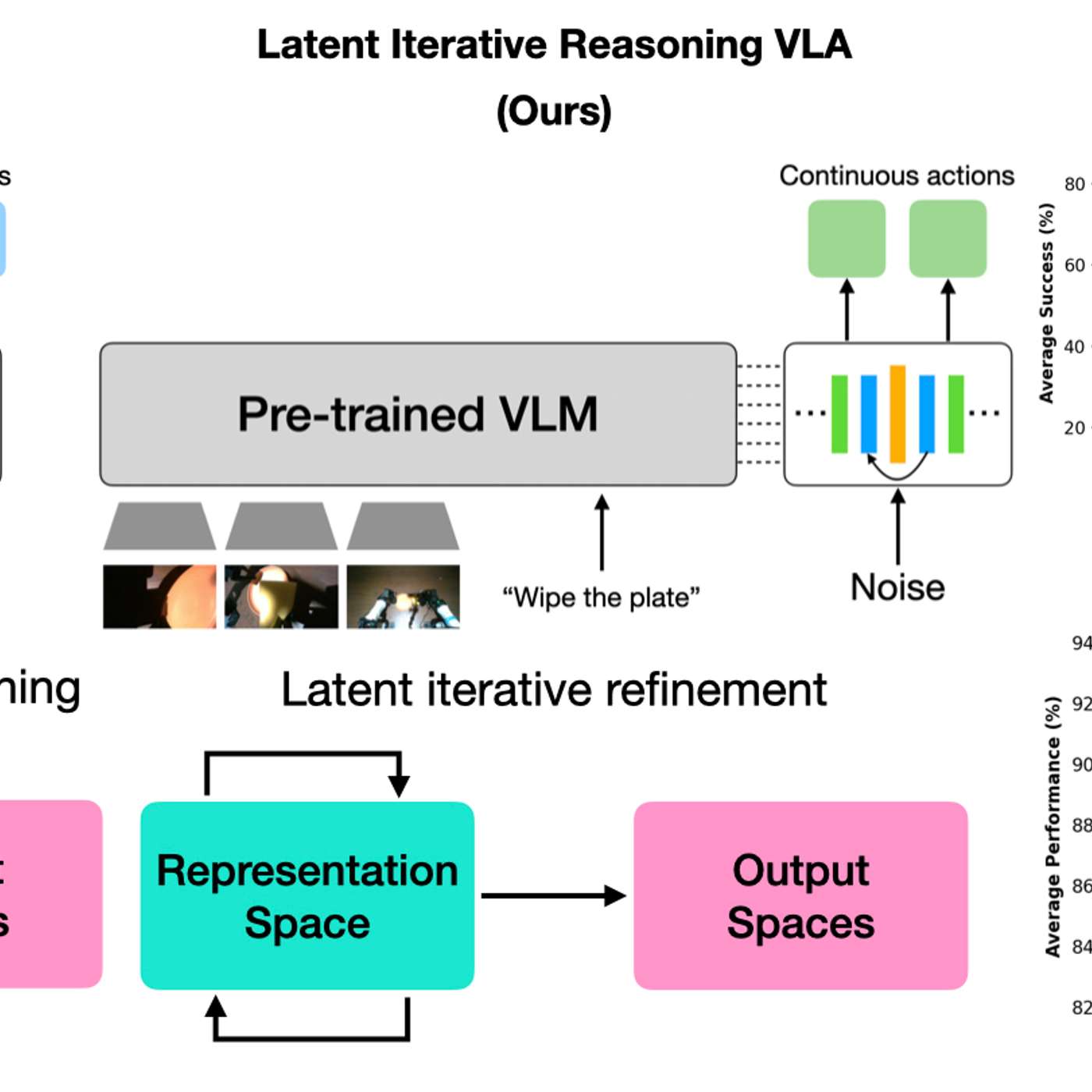
By having AI models 'think' in a hidden latent space, robots gain efficiency without generating slow, text-based reasoning. This creates a black box, making it impossible for humans to understand the robot's logic, which is a major concern for safety-critical applications where interpretability is crucial.
When determining what data an RL model should consider, resist including every available feature. Instead, observe how experienced human decision-makers reason about the problem. Their simplified mental models reveal the core signals that truly drive outcomes, leading to more stable, faster-learning, and more interpretable AI systems.

A forward pass in a large model might generate rich but fragmented internal data. Reinforcement learning (RL), especially methods like Constitutional AI, forces the model to achieve self-coherence. This process could be what unifies these fragments into a singular "unity of apperception," or consciousness.

Unlike traditional software, large language models are not programmed with specific instructions. They evolve through a process where different strategies are tried, and those that receive positive rewards are repeated, making their behaviors emergent and sometimes unpredictable.

Efforts to understand an AI's internal state (mechanistic interpretability) simultaneously advance AI safety by revealing motivations and AI welfare by assessing potential suffering. The goals are aligned through the shared need to "pop the hood" on AI systems, not at odds.
