Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Testing reveals that the fastest AI tool for text-to-3D generation is the slowest for image-to-3D, and vice versa. This performance inversion means that benchmarks for one input mode are irrelevant and misleading for evaluating the other, as they are effectively different systems.

Related Insights
Unlike simple classification (one pass), generative AI performs recursive inference. Each new token (word, pixel) requires a full pass through the model, turning a single prompt into a series of demanding computations. This makes inference a major, ongoing driver of GPU demand, rivaling training.

The computational requirements for generative media scale dramatically across modalities. If a 200-token LLM prompt costs 1 unit of compute, a single image costs 100x that, and a 5-second video costs another 100x on top of that—a 10,000x total increase. 4K video adds another 10x multiplier.

An AI model's operating environment—its "harness"—is now the primary driver of capability. Benchmarks show the same model achieves vastly different results in different harnesses, proving that the runtime, tools, and state management are as critical as the model's internal weights for achieving results.

A unified tokenizer, while efficient, may not be optimal for both understanding and generation tasks. The ideal data representation for one task might differ from the other, potentially creating a performance bottleneck that specialized models would avoid.
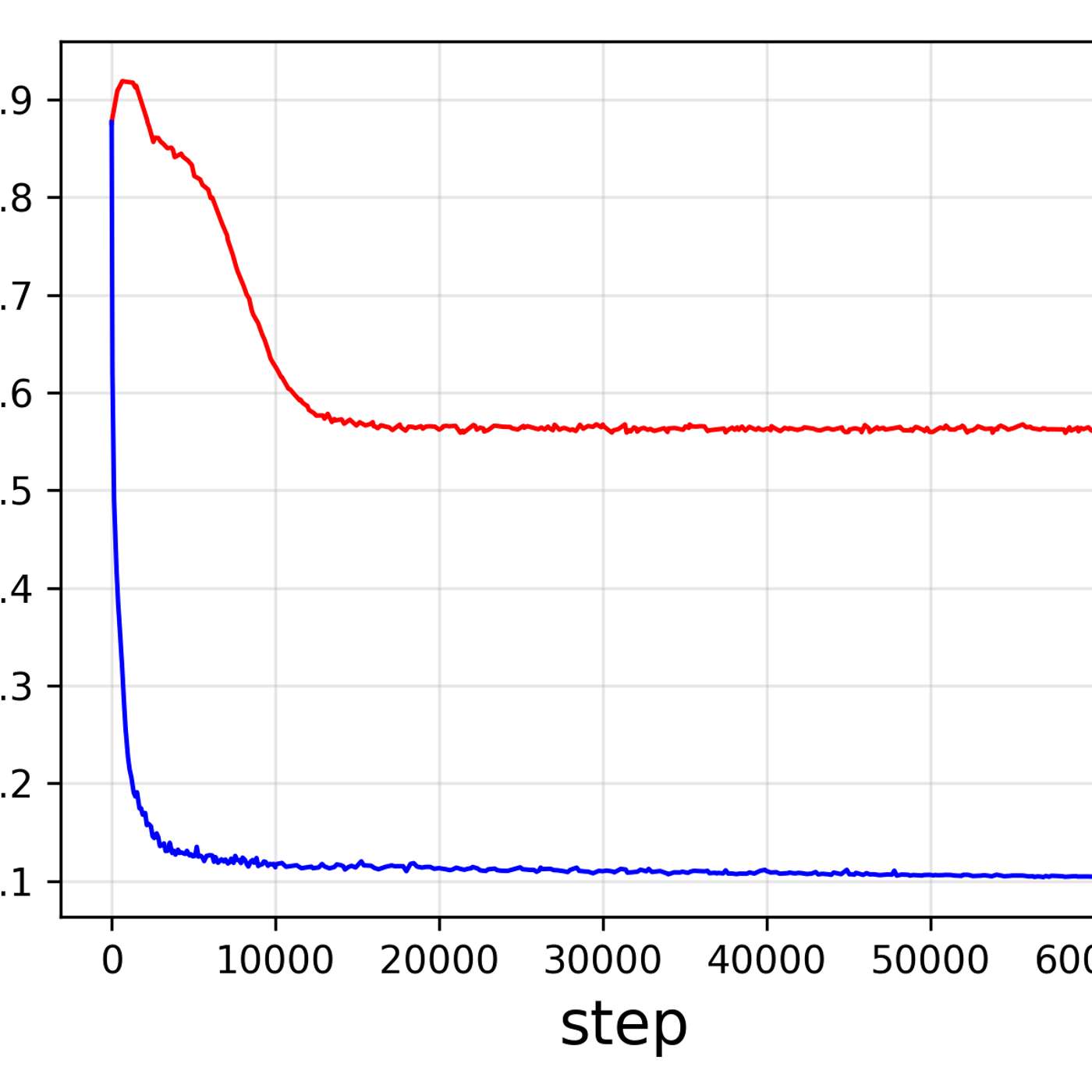
Seemingly simple benchmarks yield wildly different results if not run under identical conditions. Third-party evaluators must run tests themselves because labs often use optimized prompts to inflate scores. Even then, challenges like parsing inconsistent answer formats make truly fair comparison a significant technical hurdle.

Current multimodal models shoehorn visual data into a 1D text-based sequence. True spatial intelligence is different. It requires a native 3D/4D representation to understand a world governed by physics, not just human-generated language. This is a foundational architectural shift, not an extension of LLMs.

Comparing AI models based on single, identical prompts is a flawed methodology. A true evaluation involves 'driving' the model through multiple iterations of feedback and correction. This reveals its ability to understand and adapt to your specific intent, which is a far more critical measure of its utility than a single probabilistic output.

The ranking of AI 3D generators changes dramatically when textures are considered. A tool leading in 'white mesh' shape accuracy can fall behind others in textured output quality. This forces teams to evaluate tools separately for geometry and texturing based on their specific pipeline needs.
Popular AI coding benchmarks can be deceptive because they prioritize task completion over efficiency. A model that uses significantly more tokens and time to reach a solution is fundamentally inferior to one that delivers an elegant result faster, even if both complete the task.
Unlike streaming text from LLMs, image generation forces users to wait. An A/B test by one of Fal's customers proved that increased latency directly harms user engagement and the number of images created, much like slow page loads hurt e-commerce sales.