Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Google is heavily investing in audio interaction, as seen in its "Gemini mic" feature. The ability to "ramble" at a model to generate code or structured content is seen as a fast-growing and powerful paradigm. This moves beyond simple voice commands to using natural, unstructured speech as a primary input for creative and technical work.

Related Insights
Google's NotebookLM now generates "cinematic video overviews," a leap beyond simple slideshows. By orchestrating its Gemini models to act as a "creative director" for narrative and style, Google is strategically demonstrating its leadership in multimodal AI with a practical, high-value application that differentiates it from competitors.

To feed AI models the rich context they require, advanced users are shifting from typing to speaking. They use high-fidelity, noise-canceling microphones to 'whisper' detailed prompts, dramatically increasing the amount of information provided per second and improving AI output quality.

The current focus on LLMs is a temporary phase. The true leap towards AGI will come from multi-sensory models that can process and integrate visual, auditory, and other data streams simultaneously, much like a human does. This moves AI from text generation to real-world understanding.

The interface for AI agents is becoming nearly frictionless. By setting up a voice-to-voice loop via an app like Telegram, users can issue complex commands by simply holding down a button and speaking. This model removes the cognitive load of typing and makes interaction more natural and immediate.

Instead of typing, dictating prompts for AI coding tools allows for faster and more detailed instructions. Speaking your thought process naturally includes more context and nuance, which leads to better results from the AI. Tools like Whisperflow are optimized with developer terminology for higher accuracy.

Even with state-of-the-art models, achieving top-tier product experiences like the original Gemini audio overview hinges on sophisticated prompt engineering. The dialogue's coherence was achieved by a team that knew how to "prompt whisper" the model, showing that deep product integration requires more than just calling a powerful API.
Unlike past speech recognition that failed by requiring precise syntax, modern AI assistants can interpret natural, conversational language. They infer the user's intent, successfully translating it into code without needing perfectly dictated syntax like angle brackets or semicolons.
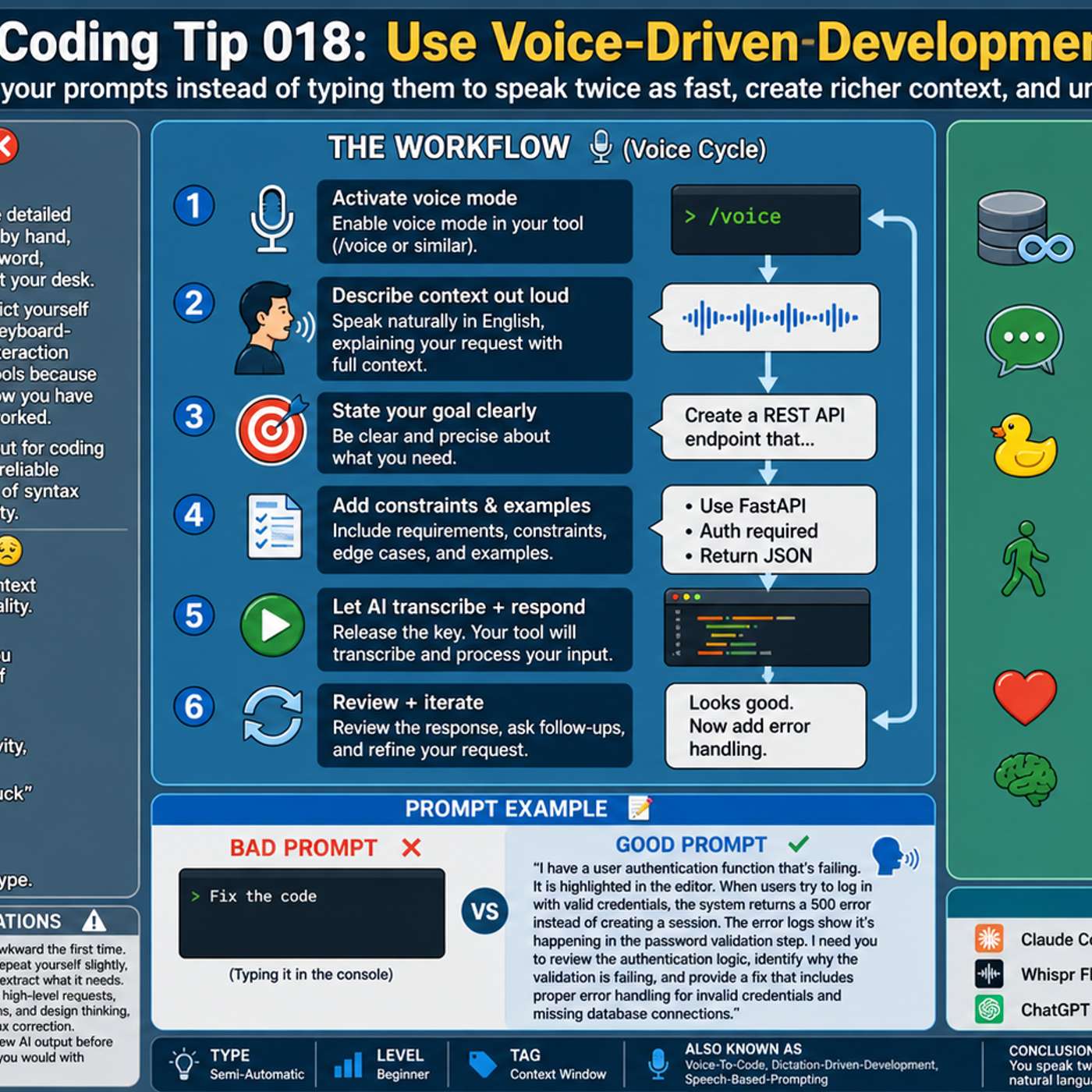
Gabor dictates long, detailed prompts to his AI agents. This allows him to provide significantly more context, nuance, and specific constraints than would be practical to type. The AI can parse the verbose input, leading to a much better-specified final product.

Using speech-to-text to talk to an AI is not just about speed. The 'art of the ramble' allows you to provide messy, uncertain, and richer context that you would filter out when typing. This gives the model access to your unpolished thought process, enabling it to help clarify your thinking and produce better results.
New AI research focuses on "interaction models" that handle real-time, full-duplex audio. This allows an AI to respond even while the user is still speaking—a significant step beyond current turn-based models and closer to the fluid, overlapping nature of natural human conversation.
