Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
To combat rising AI costs, firms are creating hybrid systems that use cheaper "worker" models for routine tasks while delegating complex problems to powerful "advisor" models. This approach, used by Harvey and explored by Microsoft, can outperform state-of-the-art models alone for a fraction of the cost.

Related Insights
Faced with rising costs from proprietary labs, sophisticated enterprise clients are building internal evaluation and routing systems. This allows them to use cheaper, open-source models for less complex tasks, optimizing for both cost and performance.

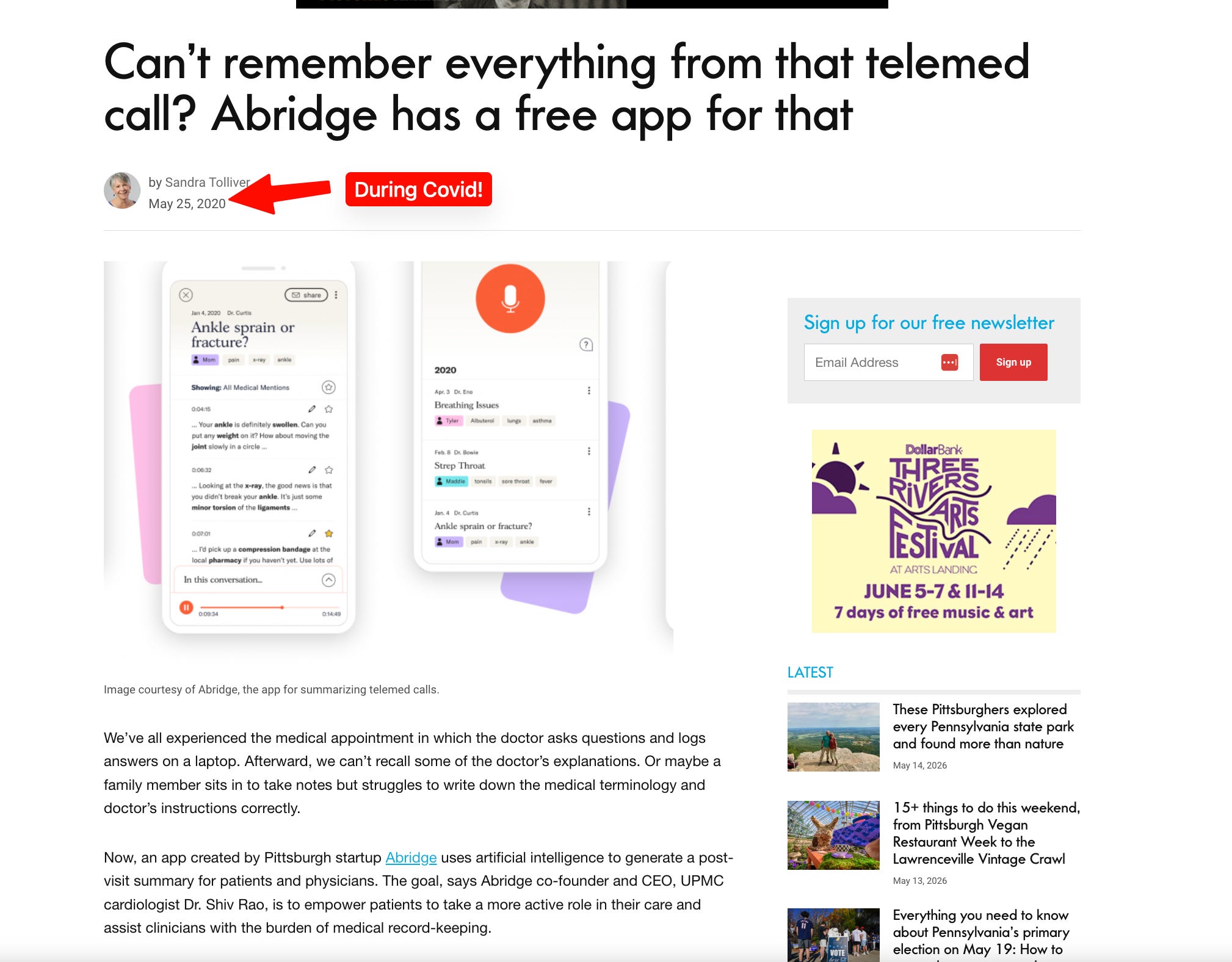
To provide high-quality AI insights in real-time without prohibitive costs, Abridge employs a "fast and slow" thinking approach. It uses a constellation of models, where a cheaper, faster model first triages a situation and then hands off complex tasks to a more powerful, expensive model only when necessary.
Advanced AI architectures will use small, fast, and cheap local models to act as intelligent routers. These models will first analyze a complex request, formulate a plan, and then delegate different sub-tasks to a fleet of more powerful or specialized models, optimizing for cost and performance.

The most sophisticated AI users aren't locking into one provider. Faced with a 13x annual increase in token costs, they leverage multiple models and routing platforms like OpenRouter to optimize for price and performance. This behavior suggests a future of model commoditization, not monopoly.

Relying solely on premium models like Claude Opus can lead to unsustainable API costs ($1M/year projected). The solution is a hybrid approach: use powerful cloud models for complex tasks and cheaper, locally-hosted open-source models for routine operations.

An intelligent AI orchestration layer can achieve a cost-to-accuracy balance superior to any single model. By routing queries to a portfolio of different models (large, small, specialized), it creates a new Pareto frontier, delivering higher success rates at a lower average cost than relying on one "best" model.

Legal AI firm Harvey proved a hybrid system—using a smaller model as a primary worker and routing selectively to a frontier model as an "advisor"—can beat a frontier-only approach on both quality and cost. This demonstrates that intelligent orchestration is a more effective strategy than simply using the most powerful model for every task.
To optimize costs, users configure powerful models like Claude Opus as the 'brain' to strategize and delegate execution tasks (e.g. coding) to cheaper, specialized models like ChatGPT's Codec, treating them as muscles.

A hybrid approach to AI agent architecture is emerging. Use the most powerful, expensive cloud models like Claude for high-level reasoning and planning (the "CEO"). Then, delegate repetitive, high-volume execution tasks to cheaper, locally-run models (the "line workers").

As enterprises scale AI, the high inference costs of frontier models become prohibitive. The strategic trend is to use large models for novel tasks, then shift 90% of recurring, common workloads to specialized, cost-effective Small Language Models (SLMs). This architectural shift dramatically improves both speed and cost.
