Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
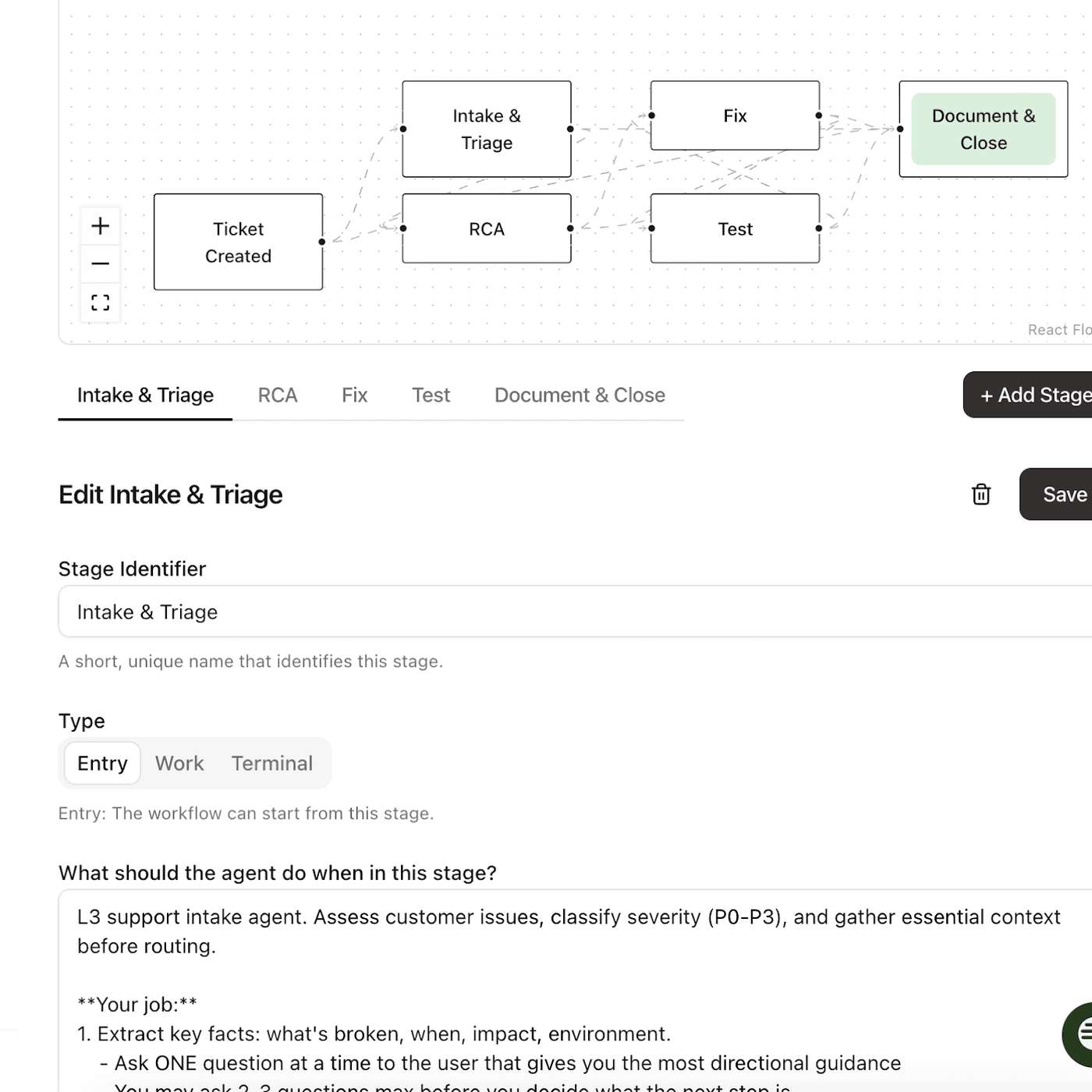
OpenAI structures its repositories to be a complete, self-contained knowledge base for AI agents. All project artifacts—design docs, historical implementation plans, and even text versions of external library documentation—are checked in, allowing the agent to find any needed context via simple search.

Related Insights
To prevent an AI agent from repeating mistakes across coding sessions, create 'agents.md' files in your codebase. These act as a persistent memory, providing context and instructions specific to a folder or the entire repo. The agent reads these files before working, allowing it to learn from past iterations and improve over time.

Company lore and the 'why' behind technical decisions often disappear when employees leave. An AI agent can analyze the entire codebase and its commit history to answer questions and reconstruct narratives, effectively turning your repo into a searchable archive.

Use an AI assistant like Claude Code to create a persistent corporate memory. Instruct it to save valuable artifacts like customer quotes, analyses, and complex SQL queries into a dedicated Git repository. This makes critical, unstructured information easily searchable and reusable for future AI-driven tasks.

Manage collective team context—docs, queries, research—in a version-controlled repository. Everyone, including non-technical members like ops and strategy, contributes via pull requests, creating a single, evolving source of truth for AI agents and humans.
Instead of using siloed note-taking apps, structure all your knowledge—code, writing, proposals, notes—into a single GitHub monorepo. This creates a unified, context-rich environment that any AI coding assistant can access. This approach avoids vendor lock-in and provides the AI with a comprehensive "second brain" to work from.

Moving PRDs and other product artifacts from Confluence or Notion directly into the codebase's repository gives AI coding assistants persistent, local context. This adjacency means the AI doesn't need external tool access (like an MCP) to understand the 'why' behind the code, leading to better suggestions and iterations.

The evolution of software from human-written code to AI-driven systems requires a new platform. This platform will manage development as a "system graph" or "knowledge graph," a higher abstraction than GitHub's file-based model. OpenAI's internal tool signals this shift away from traditional source control.

The AI's power stems from creating a holistic knowledge graph. It integrates deep codebase analysis—including regressions and fixes—with contextual data from project management and support tools like Jira and Zendesk. This mimics how a top-tier human engineer synthesizes disparate information to solve problems.
Build a repository of small, functional tools and research projects. This 'hoard' serves as a powerful, personalized context for AI agents. You can direct them to consult and combine these past solutions to tackle new, complex problems, effectively weaponizing your accumulated experience.

Early AI agents like OpenClaw use simple markdown files for memory. This 'janky' approach is effective because it mirrors a code repository, providing a rich mix of context and random access that agents, trained on code, can efficiently navigate using familiar tools like GREP.
