Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Don't let LLMs make raw HTTP calls. Instead, provide a code execution tool with a statically typed SDK. This environment can run a type-checker, instantly catching errors when the model hallucinates a non-existent endpoint or parameter, then provide helpful, in-context documentation to correct its mistake.

Related Insights
A practical hack to improve AI agent reliability is to avoid built-in tool-calling functions. LLMs have more training data on writing code than on specific tool-use APIs. Prompting the agent to write and execute the code that calls a tool leverages its core strength and produces better outcomes.

Making an API usable for an LLM is a novel design challenge, analogous to creating an ergonomic SDK for a human developer. It's not just about technical implementation; it requires a deep understanding of how the model "thinks," which is a difficult new research area.

Don't give LLMs full control. Use deterministic code for core logic, validation, and enforcing rules. Delegate only tasks requiring flexibility or understanding of unstructured input to the LLM, treating it as a specialized component, not the entire system.
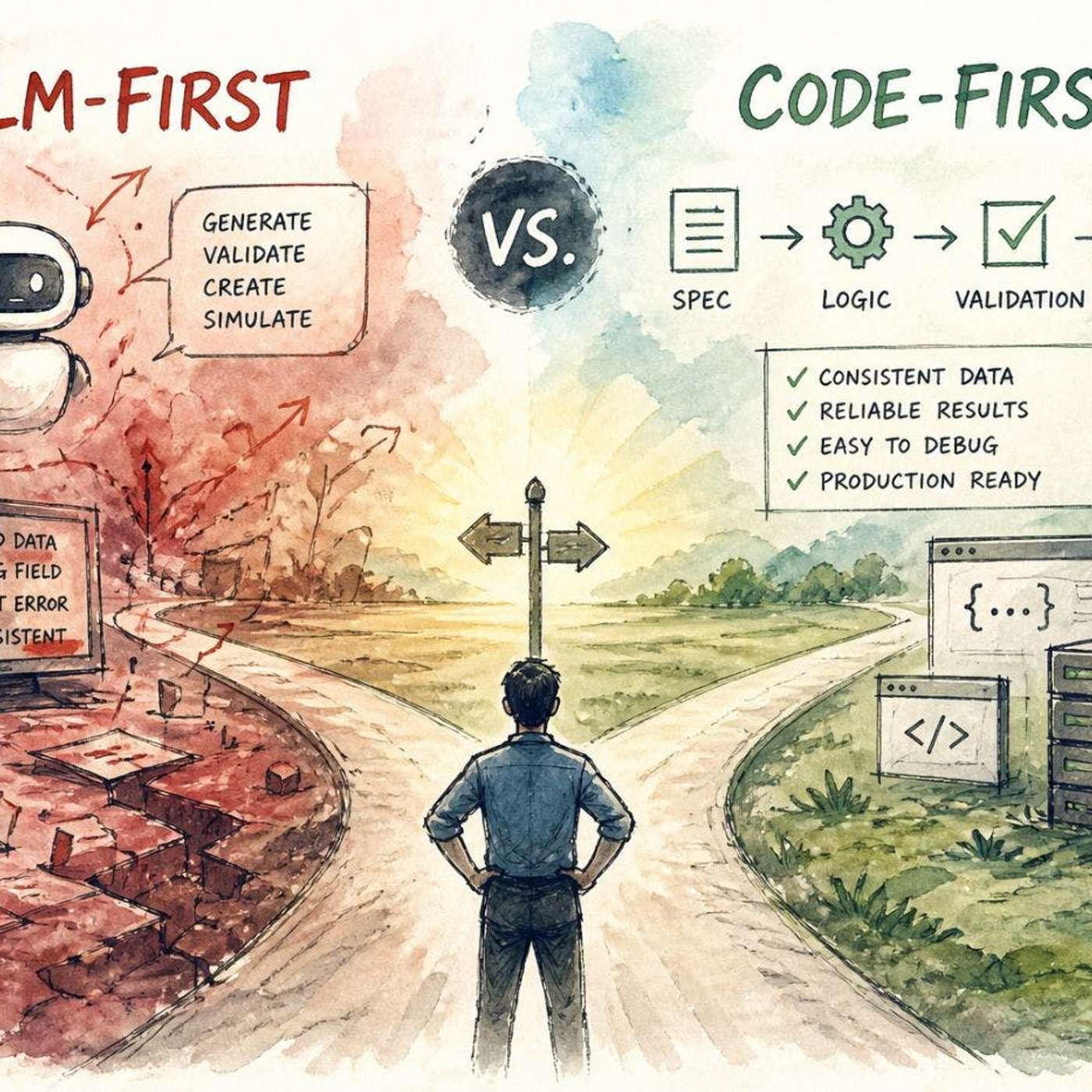
Claude Skills aren't limited to natural language instructions; they can reference and execute Python scripts. This enables developers to enforce consistency for technical tasks like data cleaning or validation, preventing the variability that occurs when the LLM generates code on its own.

To ensure reliability in healthcare, ZocDoc doesn't give LLMs free rein. It wraps them in a hybrid system where traditional, deterministic code orchestrates the AI's tasks, sets firm boundaries, and knows when to hand off to a human, preventing the 'praying for the best' approach common with direct LLM use.

To solve for AI hallucinations in high-stakes decisions, advanced platforms use the LLM as an interpreter that writes code to query raw data. If data is unavailable, it returns an error instead of fabricating an answer, making every analysis fully auditable and grounded in verifiable data.

To maximize an AI agent's effectiveness, establish foundational software engineering practices like typed languages, linters, and tests. These tools provide the necessary context and feedback loops for the AI to identify, understand, and correct its own mistakes, making it more resilient.

Use 'stop hooks' in Claude Code to create an automated quality gate. After code generation, the hook runs checks like type checking or linting. If errors exist, the output is fed back to the AI with a prompt to fix them, creating a self-correcting workflow.

Instead of giving an LLM hundreds of specific tools, a more scalable "cyborg" approach is to provide one tool: a sandboxed code execution environment. The LLM writes code against a company's SDK, which is more context-efficient, faster, and more flexible than multiple API round-trips.
A common misconception is that LLMs can directly perform actions. In reality, a model can only output text. This text is a request to an external software system, called a 'harness,' which then interprets the request and executes the action (e.g., calling an API) on the model's behalf.
