Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Top LLMs like Claude 3 and DeepSeek score 0% on complex Sudoku puzzles, a task humans can solve. This isn't a minor flaw but a categorical failure, exposing the transformer architecture's inability to handle constraint satisfaction problems that require backtracking and parallel reasoning, unlike its sequential, token-by-token processing.

Related Insights
AI models struggle to plan at different levels of abstraction simultaneously. They can't easily move from a high-level goal to a detailed task and then back up to adjust the high-level plan if the detail is blocked, a key aspect of human reasoning.

LLMs predict the next token in a sequence. The brain's cortex may function as a general prediction engine capable of "omnidirectional inference"—predicting any missing information from any available subset of inputs, not just what comes next. This offers a more flexible and powerful form of reasoning.

Pathway's BDH model achieves 97.4% accuracy on extreme Sudoku at 10x lower cost than LLMs that get 0%. It avoids burning GPU cycles on generating text-based, step-by-step thoughts (Chain of Thought) by reasoning within its internal latent space. This demonstrates a massive economic advantage for non-transformer architectures on complex reasoning tasks.
LLMs shine when acting as a 'knowledge extruder'—shaping well-documented, 'in-distribution' concepts into specific code. They fail when the core task is novel problem-solving where deep thinking, not code generation, is the bottleneck. In these cases, the code is the easy part.

Success on constraint-satisfaction puzzles like Sudoku signals a shift from current AI that summarizes existing information to a new class capable of 'generative strategy.' These models can analyze constraints and creatively propose novel solutions, tackling real-world planning problems in medicine, law, and operations rather than just describing what's already known.
Advanced AI models exhibit profound cognitive dissonance, mastering complex, abstract tasks while failing at simple, intuitive ones. An Anthropic team member notes Claude solves PhD-level math but can't grasp basic spatial concepts like "left vs. right" or navigating around an object in a game, highlighting the alien nature of their intelligence.

Google DeepMind CEO Demis Hassabis argues that today's large models are insufficient for AGI. He believes progress requires reintroducing algorithmic techniques from systems like AlphaGo, specifically planning and search, to enable more robust reasoning and problem-solving capabilities beyond simple pattern matching.

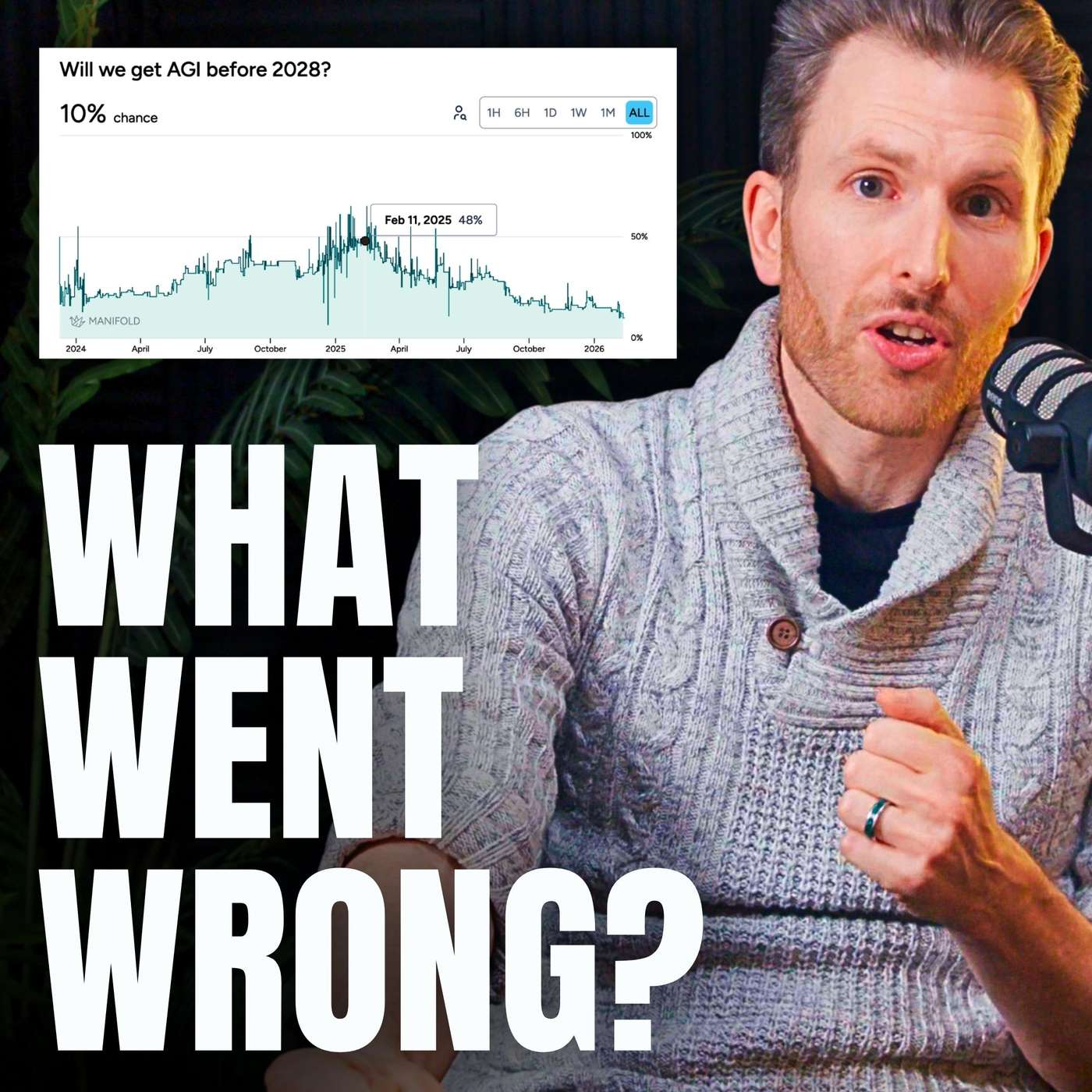
Hopes that AI's new reasoning skills in checkable domains like math and code would generalize to ambiguous, real-world tasks like booking a flight did not materialize. This failure of 'reasoning generalization' was a major technical roadblock that forced experts to lengthen AGI timelines.
To improve LLM reasoning, researchers feed them data that inherently contains structured logic. Training on computer code was an early breakthrough, as it teaches patterns of reasoning far beyond coding itself. Textbooks are another key source for building smaller, effective models.

Replit's CEO argues that today's LLMs are asymptoting on general reasoning tasks. Progress continues only in domains with binary outcomes, like coding, where synthetic data can be generated infinitely. This indicates a fundamental limitation of the current 'ingest the internet' approach for achieving AGI.
